# 函数式编程
- 函数编程思维
- 函数式编程常用核心概念
- 当下函数式编程最热的库
- 函数式编程的实际应用场景
# 函数式编程思维
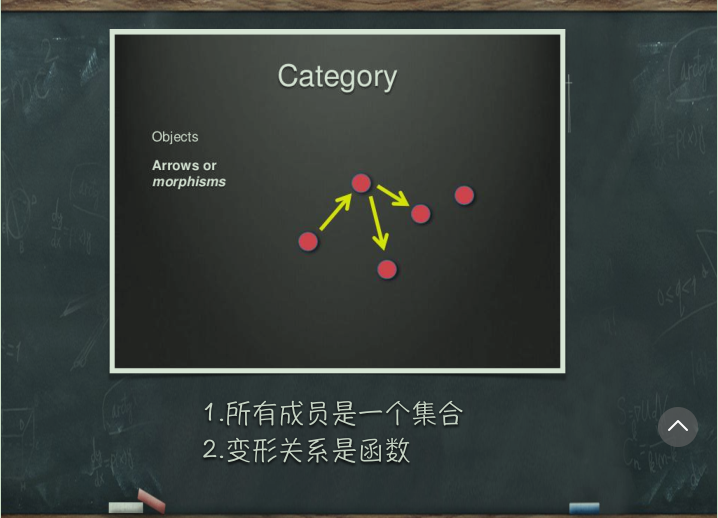
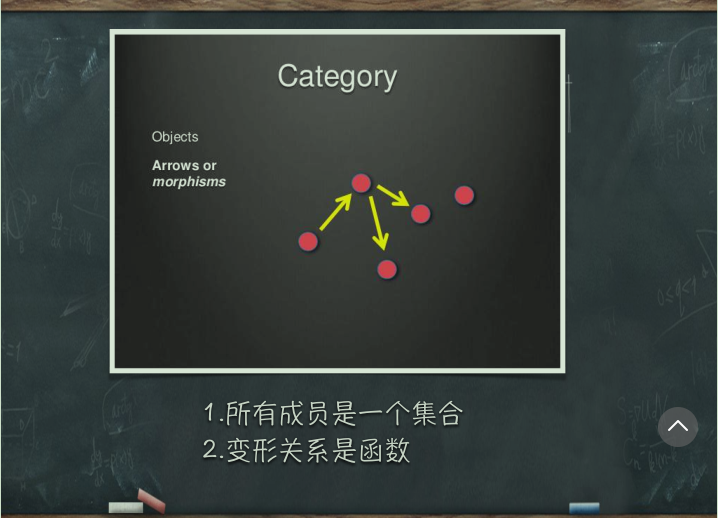
# 范畴论
- 函数式编程是范畴论的数学分支是一门很复杂的数学,认为世界上所有概念体系都可以抽象出一个个范畴
- 彼此之间存在某种关系概念、事务、对象等等,都构成范畴。任何事物只要找出他们之间的关系,就能定义。3.箭头表示范畴成员之间的关系,正式名称叫做 "态射" 。范畴论认为,同一个范畴的所有成员,就是不同状态的变形关系。通过 "态射" ,一个成员可以变形成另一种成员。
# 函数编程基础理论
1.函数式编程(Functional Programming)其实相对于计算机的历史而 言是一个非常古老的概念,甚至早于第一台计算机的诞生。函数式 编程的基础模型来源于 λ (Lambda x=>x*2)演算,而 λ 演算并非设计 于在计算机上执行,它是在 20 世纪三十年代引入的一套用于研究 函数定义、函数应用和递归的形式系统。
2.函数式编程不是用函数来编程,也不是传统的面向过程编程。主 旨在于将复杂的函数符合成简单的函数(计算理论,或者递归论, 或者拉姆达演算)。运算过程尽量写成一系列嵌套的函数调用
3.JavaScript 是披着 C 外衣的 Lisp。
4.真正的火热是随着React的高阶函数而逐步升温。
# 一等公民的函数
1.函数是一等公民。所谓”第一等公民”(first class),指的是函数 与其他数据类型一样,处于平等地位,可以赋值给其他变量,也可以作为参数,传入另一个函数,或者作为别的函数的返回值。
2.不可改变量。在函数式编程中,我们通常理解的变量在函数式 编程中也被函数代替了:在函数式编程中变量仅仅代表某个表达 式。这里所说的’变量’是不能被修改的。所有的变量只能被赋一次 初值
3.map & reduce他们是最常用的函数式编程的方法。
为啥钟爱一等公民
- 函数是”第一等公民”
- 只用”表达式",不用"语句"
- 提高维护和检索代码的成本
- 注意:命名用通用性高的,要注意this(bind一下)
// 这行
ajaxCall(json => callback(json));
// 等价于这行
ajaxCall(callback);
// 那么,重构下 getServerStuff
const getServerStuff = callback => ajaxCall(callback);
// ...就等于
const getServerStuff = ajaxCall // <-- 看,没有括号哦
//例子二
const BlogController = {
index(posts) { return Views.index(posts); },
show(post) { return Views.show(post); },
create(attrs) { return Db.create(attrs); }
}
--------------重写--------
const BlogController = {
index: Views.index,
show: Views.show,
create: Db.create,
update: Db.update,
destroy: Db.destroy,
};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
# 函数式编程常用核心概念
# 纯函数
概念: 对于相同的输入,永远会得到相同的输出,而且没有任何可观察的副作用,也不依赖外部环境的状态。
var xs = [1,2,3,4,5];
// 纯的
xs.slice(0,3);
//=> [1,2,3]
xs.slice(0,3);
//=> [1,2,3]
xs.slice(0,3);
//=> [1,2,3]
// 不纯的
xs.splice(0,3);
//=> [1,2,3]
xs.splice(0,3);
//=> [4,5]
xs.splice(0,3);
//=> []
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
优点缺点:
- 没有”副作用"
- 不修改状态
- 引用透明(函数运行只靠参数)
# 

# 纯度和幂等性
幂等性是指执行无数次后还具有相同的效果,同一的参 数运行一次函数应该与连续两次结果一致。幂等性在函 数式编程中与纯度相关,但有不一致。
Math.abs(Math.abs(-42))
# 追求“纯”的理由
- 可缓存性
一个简单的实现
var memoize = function(f) {
var cache = {};
return function() {
var arg_str = JSON.stringify(arguments);
cache[arg_str] = cache[arg_str] || f.apply(f, arguments);
return cache[arg_str];
};
};
2
3
4
5
6
7
8
9
- 可移植性/自文档化
纯函数是完全自给自足的,它需要的所有东西都能轻易获得。仔细思考思考这一点...这种自给自足的好处是什么呢?首先,纯函数的依赖很明确,因此更易于观察和理解——没有偷偷摸摸的小动作。
// 不纯的
var signUp = function(attrs) {
var user = saveUser(attrs);
welcomeUser(user);
};
var saveUser = function(attrs) {
var user = Db.save(attrs);
...
};
var welcomeUser = function(user) {
Email(user, ...);
...
};
// 纯的
var signUp = function(Db, Email, attrs) {
return function() {
var user = saveUser(Db, attrs);
welcomeUser(Email, user);
};
};
var saveUser = function(Db, attrs) {
...
};
var welcomeUser = function(Email, user) {
...
};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
- 可测试性
第三点,纯函数让测试更加容易。我们不需要伪造一个“真实的”支付网关,或者每一次测试之前都要配置、之后都要断言状态(assert the state)。只需简单地给函数一个输入,然后断言输出就好了。
事实上,我们发现函数式编程的社区正在开创一些新的测试工具,能够帮助我们自动生成输入并断言输出。这超出了本书范围,但是我强烈推荐你去试试 Quickcheck——一个为函数式环境量身定制的测试工具。
- 合理性
很多人相信使用纯函数最大的好处是引用透明性(referential transparency)。如果一段代码可以替换成它执行所得的结果,而且是在不改变整个程序行为的前提下替换的,那么我们就说这段代码是引用透明的。
由于纯函数总是能够根据相同的输入返回相同的输出,所以它们就能够保证总是返回同一个结果,这也就保证了引用透明性。
- 并行代码
最后一点,也是决定性的一点:我们可以并行运行任意纯函数。因为纯函数根本不需要访问共享的内存,而且根据其定义,纯函数也不会因副作用而进入竞争态(race condition)。
并行代码在服务端 js 环境以及使用了 web worker 的浏览器那里是非常容易实现的,因为它们使用了线程(thread)。不过出于对非纯函数复杂度的考虑,当前主流观点还是避免使用这种并行。
# 偏函数的应用(“局部应用”、“部分应用”、“偏应用)
- 传递给函数一部分参数来调用它,让它返回一个函数去处理剩下的参数。
- 偏函数之所以“偏”,在就在于其只能处理那些能与至少一个case语句匹配的输入,而不能处理所有可能的输入。
// 带⼀个函数参数 和 该函数的部分参数
const partial = (f, ...args) =>
(...moreArgs) =>
f(...args, ...moreArgs)
const add3 = (a, b, c) => a + b + c
// 偏应⽤ `2` 和 `3` 到 `add3` 给你⼀个单参数的函数
const fivePlus = partial(add3, 2, 3)
fivePlus(4)
//bind实现
const add1More = add3.bind(null, 2, 3) // (c) => 2 + 3 + c
2
3
4
5
6
7
8
9
10
# 函数柯里化
维基百科上说道:柯里化,英语:Currying(果然是满满的英译中的既视感),是把接受多个参数的函数变换成接受一个单一参数(最初函数的第一个参数)的函数,并且返回接受余下的参数而且返回结果的新函数的技术。
- 柯里化(Curried) 通过偏应用函数实现。
- 传递给函数一部分参数来调用它,让它返回一个函数去 处理剩下的参数。
看这个解释有一点抽象,我们就拿被做了无数次示例的add函数,来做一个简单的实现。
//普通的add函数
function(a,b){
return a+b
}
//Currying后
function curryingAdd(a){
return function(b){
return a+b
}
}
add(1, 2) // 3
curryingAdd(1)(2) // 3
2
3
4
5
6
7
8
9
10
11
12
13
14
实际上就是把add函数的x,y两个参数变成了先用一个函数接收x然后返回一个函数去处理y参数。现在思路应该就比较清晰了,就是只传递给函数一部分参数来调用它,让它返回一个函数去处理剩下的参数。 但是问题来了费这么大劲封装一层,到底有什么用处呢?没有好处想让我们程序员多干事情是不可能滴,这辈子都不可能.
来列一列Currying有哪些好处呢?
1. 参数复用
// 正常正则验证字符串 reg.test(txt)
// 函数封装后
function check(reg, txt) {
return reg.test(txt)
}
check(/\d+/g, 'test') //false
check(/[a-z]+/g, 'test') //true
// Currying后
function curryingCheck(reg) {
return function(txt) {
return reg.test(txt)
}
}
var hasNumber = curryingCheck(/\d+/g)
var hasLetter = curryingCheck(/[a-z]+/g)
hasNumber('test1') // true
hasNumber('testtest') // false
hasLetter('21212') // false
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
上面的示例是一个正则的校验,正常来说直接调用check函数就可以了,但是如果我有很多地方都要校验是否有数字,其实就是需要将第一个参数reg进行复用,这样别的地方就能够直接调用hasNumber,hasLetter等函数,让参数能够复用,调用起来也更方便。
2. 提前确认
var on = function(element, event, handler) {
if (document.addEventListener) {
if (element && event && handler) {
element.addEventListener(event, handler, false);
}
} else {
if (element && event && handler) {
element.attachEvent('on' + event, handler);
}
}
}
var on = (function() {
if (document.addEventListener) {
return function(element, event, handler) {
if (element && event && handler) {
element.addEventListener(event, handler, false);
}
};
} else {
return function(element, event, handler) {
if (element && event && handler) {
element.attachEvent('on' + event, handler);
}
};
}
})();
//换一种写法可能比较好理解一点,上面就是把isSupport这个参数给先确定下来了
var on = function(isSupport, element, event, handler) {
isSupport = isSupport || document.addEventListener;
if (isSupport) {
return element.addEventListener(event, handler, false);
} else {
return element.attachEvent('on' + event, handler);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
3. 延迟运行
Function.prototype.bind = function (context) {
var _this = this
var args = Array.prototype.slice.call(arguments, 1)
return function() {
return _this.apply(context, args)
}
}
2
3
4
5
6
7
8
一些性能问题
存取arguments对象通常要比存取命名参数要慢一点 一些老版本的浏览器在arguments.length的实现上是相当慢的 使用fn.apply( … ) 和 fn.call( … )通常比直接调用fn( … ) 稍微慢点 创建大量嵌套作用域和闭包函数会带来花销,无论是在内存还是速度上
总结:事实上柯里化是一种“预加载”函数的方法,通过传递较少的参数, 得到一个已经记住了这些参数的新函数,某种意义上讲,这是一种 对参数的“缓存”,是一种非常高效的编写函数的方法
最后再扩展一道经典面试题
// 实现一个add方法,使计算结果能够满足如下预期:
add(1)(2)(3) = 6;
add(1, 2, 3)(4) = 10;
add(1)(2)(3)(4)(5) = 15;
function add() {
// 第一次执行时,定义一个数组专门用来存储所有的参数
var _args = Array.prototype.slice.call(arguments);
// 在内部声明一个函数,利用闭包的特性保存_args并收集所有的参数值
var _adder = function() {
_args.push(...arguments);
return _adder;
};
// 利用toString隐式转换的特性,当最后执行时隐式转换,并计算最终的值返回
_adder.toString = function () {
return _args.reduce(function (a, b) {
return a + b;
});
}
return _adder;
}
add(1)(2)(3) // 6
add(1, 2, 3)(4) // 10
add(1)(2)(3)(4)(5) // 15
add(2, 6)(1) // 9
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
# 代码组合
# 函数组合
这就是组合(compose,以下将称之为组合)
var compose = function(f,g) {
return function(x) {
return f(g(x));
};
};
2
3
4
5
f和 g 都是函数,x 是在它们之间通过“管道”传输的值。
组合看起来像是在饲养函数。你就是饲养员,选择两个有特点又遭你喜欢的函数,让它们结合,产下一个崭新的函数。组合的用法如下:
var toUpperCase = function(x) { return x.toUpperCase(); };
var exclaim = function(x) { return x + '!'; };
var shout = compose(exclaim, toUpperCase);
shout("send in the clowns");
//=> "SEND IN THE CLOWNS!"
2
3
4
5
6
两个函数组合之后返回了一个新函数是完全讲得通的:组合某种类型(本例中是函数)的两个元素本就该生成一个该类型的新元素。把两个乐高积木组合起来绝不可能得到一个林肯积木。所以这是有道理的,我们将在适当的时候探讨这方面的一些底层理论。
在 compose 的定义中,g 将先于 f 执行,因此就创建了一个从右到左的数据流。这样做的可读性远远高于嵌套一大堆的函数调用,如果不用组合,shout 函数将会是这样的:
var shout = function(x){
return exclaim(toUpperCase(x));
};
2
3
让代码从右向左运行,而不是由内而外运行,我觉得可以称之为“左倾”(吁——)。我们来看一个顺序很重要的例子:
var head = function(x) { return x[0]; };
var reverse = reduce(function(acc, x){ return [x].concat(acc); }, []);
var last = compose(head, reverse);
last(['jumpkick', 'roundhouse', 'uppercut']);
//=> 'uppercut'
2
3
4
5
6
reverse 反转列表,head 取列表中的第一个元素;所以结果就是得到了一个 last 函数(译者注:即取列表的最后一个元素),虽然它性能不高。这个组合中函数的执行顺序应该是显而易见的。尽管我们可以定义一个从左向右的版本,但是从右向左执行更加能够反映数学上的含义——是的,组合的概念直接来自于数学课本。实际上,现在是时候去看看所有的组合都有的一个特性了。
// 结合律(associativity)
var associative = compose(f, compose(g, h)) == compose(compose(f, g), h);
// true
2
3
这个特性就是结合律,符合结合律意味着不管你是把 g 和 h 分到一组,还是把 f 和 g 分到一组都不重要。所以,如果我们想把字符串变为大写,可以这么写:
compose(toUpperCase, compose(head, reverse));
// 或者
compose(compose(toUpperCase, head), reverse);
2
3
4
因为如何为 compose 的调用分组不重要,所以结果都是一样的。这也让我们有能力写一个可变的组合(variadic compose),用法如下:
// 前面的例子中我们必须要写两个组合才行,但既然组合是符合结合律的,我们就可以只写一个,
// 而且想传给它多少个函数就传给它多少个,然后让它自己决定如何分组。
var lastUpper = compose(toUpperCase, head, reverse);
lastUpper(['jumpkick', 'roundhouse', 'uppercut']);
//=> 'UPPERCUT'
var loudLastUpper = compose(exclaim, toUpperCase, head, reverse)
loudLastUpper(['jumpkick', 'roundhouse', 'uppercut']);
//=> 'UPPERCUT!'
2
3
4
5
6
7
8
9
10
11
12
13
运用结合律能为我们带来强大的灵活性,还有对执行结果不会出现意外的那种平和心态。至于稍微复杂些的可变组合,也都包含在本书的 support 库里了,而且你也可以在类似 lodash、underscore 以及 ramda 这样的类库中找到它们的常规定义。
结合律的一大好处是任何一个函数分组都可以被拆开来,然后再以它们自己的组合方式打包在一起。让我们来重构重构前面的例子:
var loudLastUpper = compose(exclaim, toUpperCase, head, reverse);
// 或
var last = compose(head, reverse);
var loudLastUpper = compose(exclaim, toUpperCase, last);
// 或
var last = compose(head, reverse);
var angry = compose(exclaim, toUpperCase);
var loudLastUpper = compose(angry, last);
// 更多变种...
2
3
4
5
6
7
8
9
10
11
12

# Point Free
- 把一些对象自带的方法转化成纯函数,不要命名转瞬即逝 的中间变量。
- 这个函数中,我们使用了 str 作为我们的中间变量,但 这个中间变量除了让代码变得长了一点以外是毫无意义 的。
const f = str => str.toUpperCase().split(' ');
优缺点
另外,pointfree 模式能够帮助我们减少不必要的命名,让代码保持简洁和通用。对函数式代码来说,pointfree 是非常好的石蕊试验,因为它能告诉我们一个函数是否是接受输入返回输出的小函数。比如,while 循环是不能组合的。不过你也要警惕,pointfree 就像是一把双刃剑,有时候也能混淆视听。并非所有的函数式代码都是 pointfree 的,不过这没关系。可以使用它的时候就使用,不能使用的时候就用普通函数。
# 声明式与命令式代码
命令式代码的意思就是,我们通过编写一条又一条指令去让计算 机执行一些动作,这其中一般都会涉及到很多繁杂的细节。而声 明式就要优雅很多了,我们通过写表达式的方式来声明我们想干 什么,而不是通过一步一步的指示
//命令式
let CEOs = [];
for(var i = 0; i < companies.length; i++)
CEOs.push(companies[i].CEO)
}
//声明式
let CEOs = companies.map(c => c.CEO);
2
3
4
5
6
7
优缺点
函数式编程的一个明显的好处就是这种声明式的代码,对 于无副作用的纯函数,我们完全可以不考虑函数内部是如何实 现的,专注于编写业务代码。优化代码时,目光只需要集中在 这些稳定坚固的函数内部即可。 相反,不纯的函数式的代码会产生副作用或者依赖外部系 统环境,使用它们的时候总是要考虑这些不干净的副作用。在 复杂的系统中,这对于程序员的心智来说是极大的负担
# 惰性求值、惰性函数、惰性链
在指令式语言中以下代码会按顺序执行,由于每个函数 都有可能改动或者依赖于其外部的状态,因此必须顺序 执行。
惰性求值,函数f()的调用都只会简单的返回t保留在其闭包内的值,这样执行起来非常高效(如果使用全局t存储时间对象,在每次调用函数时候必须重新求值)
var f=function(){
var t=new Date();
f=function(){
return t;
}
return f();
}
f();
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 高阶函数
高阶函数是对其他函数进行操作的函数,可以将它们作为参数或返回它们。 简单来说,高阶函数是一个函数,它接收函数作为参数或将函数作为输出返回。
更生动的描述: 函数当参数,把传入的函数做一个封装,然后返回这个封装函数,达到更高程度的抽象。 map、reduce、filter等
特点:
- 高阶函数是一等公民
- 它以一个函数作为参数
- 它以一个函数作为返回值
//命令式
var add = function(a,b){
return a + b;
};
function math(func,array){
return func(array[0],array[1]);
}
math(add,[1,2]); // 3
2
3
4
5
6
7
8
# 尾调用优化
# 尾调用
尾调用是指一个函数里的最后一个动作是返回一个函数的调用结果的情形,该调用的返回值,直接返回给函数。。(注意:尾调用不一定出现在函数尾部,只要是最后一步操作即可)
以下俩种情况不属于尾调用
//尾调用
function f(x){
return g(x);
}
// 情况一
function f(x){
let y = g(x);
return y;
}
// 情况二
function f(x){
return g(x) + 1;
}
//尾调用不一定出现在函数尾部,只要是最后一步操作即可。
function f(x) {
if (x > 0) {
return m(x)
}
return n(x);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
# 尾调用优化
我们知道,函数调用会在内存形成一个"调用记录",又称"调用帧"(call frame),保存调用位置和内部变量等信息。如果在函数A的内部调用函数B,那么在A的调用记录上方,还会形成一个B的调用记录。等到B运行结束,将结果返回到A,B的调用记录才会消失。如果函数B内部还调用函数C,那就还有一个C的调用记录栈,以此类推。所有的调用记录,就形成一个"调用栈"(call stack)。
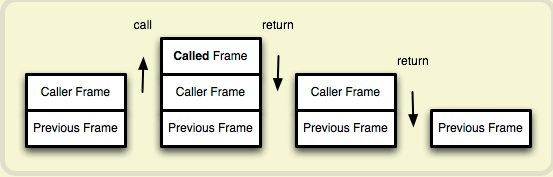
尾调用由于是函数的最后一步操作,所以不需要保留外层函数的调用记录,因为调用位置、内部变量等信息都不会再用到了,只要直接用内层函数的调用记录,取代外层函数的调用记录就可以了。
function f() {
let m = 1;
let n = 2;
return g(m + n);
}
f();
// 等同于
function f() {
return g(3);
}
f();
// 等同于
g(3);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
上面代码中,如果函数g不是尾调用,函数f就需要保存内部变量m和n的值、g的调用位置等信息。但由于调用g之后,函数f就结束了,所以执行到最后一步,完全可以删除 f() 的调用记录,只保留 g(3) 的调用记录。
这就叫做"尾调用优化"(Tail call optimization),即只保留内层函数的调用记录。如果所有函数都是尾调用,那么完全可以做到每次执行时,调用记录只有一项,这将大大节省内存。这就是"尾调用优化"的意义。
# 传统递归
简单的来说递归就是一个函数直接或间接地调用自身,是为直接或间接递归。一般来说,递归需要有边界条件、递归前进段和递归返回段。当边界条件不满足时,递归前进;当边界条件满足时,递归返回。用递归需要注意以下两点:(1) 递归就是在过程或函数里调用自身。(2) 在使用递归策略时,必须有一个明确的递归结束条件,称为递归出口。

递归一般用于解决三类问题:
- 数据的定义是按递归定义的。(Fibonacci函数,n的阶乘)
- 问题解法按递归实现。(回溯)
- 数据的结构形式是按递归定义的。(二叉树的遍历,图的搜索)
递归的缺点:
递归解题相对常用的算法如普通循环等,运行效率较低。因此,应该尽量避免使用递归,除非没有更好的算法或者某种特定情况,递归更为适合的时候。在递归调用的过程当中系统为每一层的返回点、局部量等开辟了栈来存储,因此递归次数过多容易造成栈溢出。
注意: 普通递归时,内存需要记录调用的堆栈所出的深度和位置信息。在最底层计算返回值,再根据记录的信息,跳回上一层级计算,然后再跳回更高一层,依次运行,直到最外层的调用函数。在cpu计算和内存会消耗很多,而且当深度过大时,会出现堆栈溢出
# 尾递归
函数调用自身,称为递归。如果尾调用自身,就称为尾递归。就是把当前的运算结果(或路径)放在参数里传给下层函数,深层函数所面对的不是越来越简单的问题,而是越来越复杂的问题,因为参数里带有前面若干步的运算路径。尾递归就是把当前的运算结果(或路径)放在参数里传给下层函数,深层函数所面对的不是越来越简单的问题,而是越来越复杂的问题,因为参数里带有前面若干步的运算路径。
递归非常耗费内存,因为需要同时保存成千上百个调用记录,很容易发生"栈溢出"错误(stack overflow)。但对于尾递归来说,由于只存在一个调用记录(一个函数堆栈),所以永远不会发生"栈溢出"错误。

# 尾递归优化
ES6的尾调用优化只在严格模式下开启,正常模式是无效的。
// 不是尾递归,无法优化 斐波那契数列
function factorial(n) {
if (n === 1) return 1;
return n * factorial(n - 1);
}
function factorial(n, total) {
if (n === 1) return total;
return factorial(n - 1, n * total);
} //ES6强制使用尾递归
2
3
4
5
6
7
8
9

尾递归问题:
- 尾递归的判断标准是函数运行【最后一步】是否调用自身, 而不是 是否在函数的【最后一行】调用自身, 最后一行调用其他函数 并返回叫尾调用。
- 按道理尾递归调用调用栈永远都是更新当前的栈帧而已,这
样就完全避免了爆栈的危险。但是现如今的浏览器并未完全支持
原因有二- 在引擎层面消除递归是一个隐式的行为,程序员意识不到。
- 堆栈信息丢失了 开发者难已调试。
- 既然浏览器不支持我们可以把这些递归写成while 递归需要保存大量的调用记录,很容易发生栈溢出错误,如果使用尾递归优化,将递归变为循环,那么只需要保存一个调用记录,这样就不会发生栈溢出错误了。
# 闭包

大白话理解:拿到你不应该拿到的东西,为什么这么说,本来这个东西不是你的但是在函数的私有的内部,但想取到,就用到了闭包。
小黄书的说法:保留了当前的函数执行的词法作用域,把词法作用域拿出去
# 红皮书的书法:有权访问其他函数内部变量的的函数
# 范畴与容器
# 范畴论
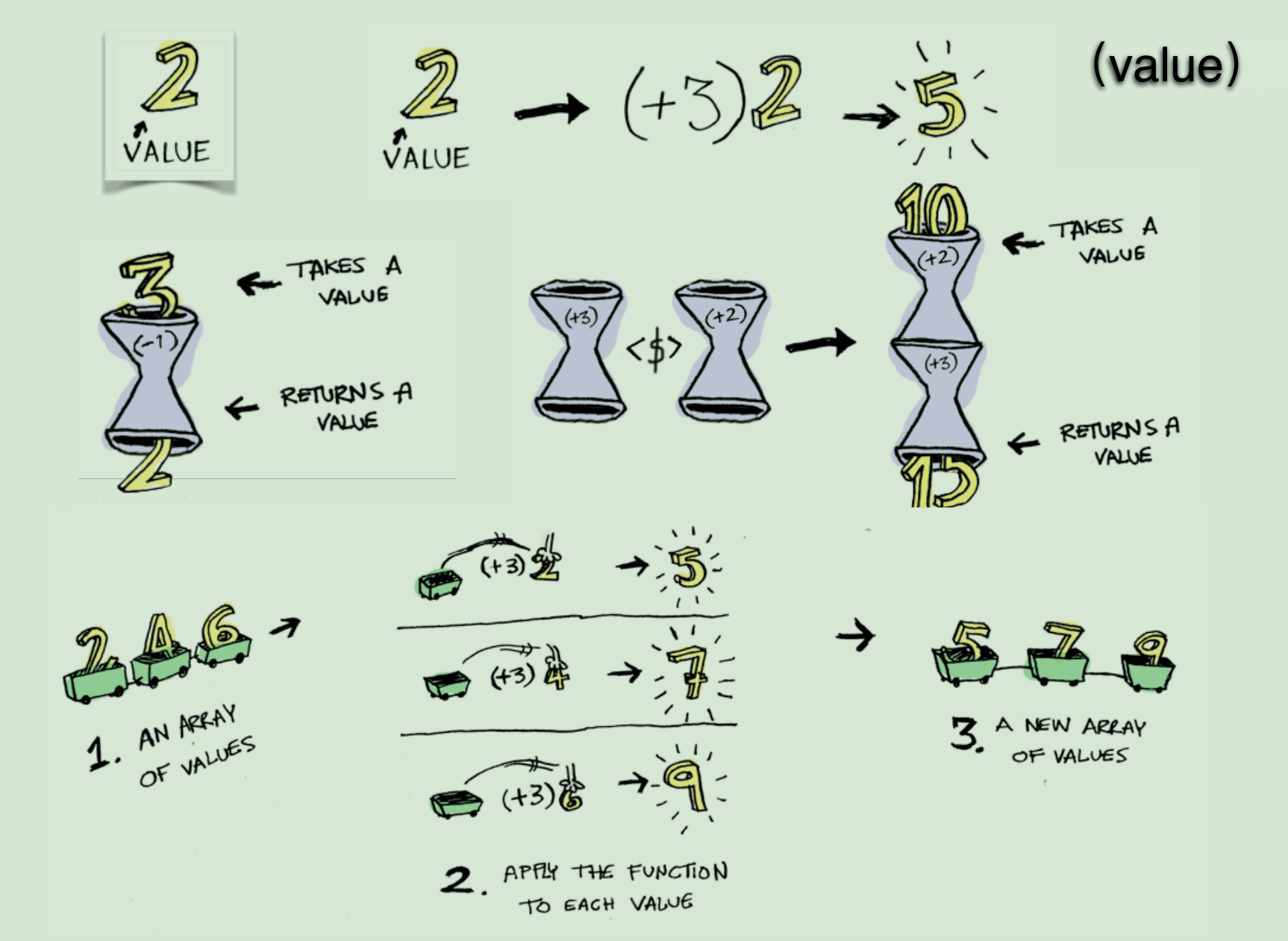
- 我们可以把”范畴”想象成是一个容器,里面包含两样东西。值 (value)、值的变形关系,也就是函数。
- 范畴论使用函数,表达范畴之间的关系。
- 伴随着范畴论的发展,就发展出一整套函数的运算方法。这套方法 起初只用于数学运算,后来有人将它在计算机上实现了,就变成了今 天的”函数式编程"。
- 本质上,函数式编程只是范畴论的运算方法,跟数理逻辑、微积 分、行列式是同一类东西,都是数学方法,只是碰巧它能用来写程 序。为什么函数式编程要求函数必须是纯的,不能有副作用?因为它 是一种数学运算,原始目的就是求值,不做其他事情,否则就无法满 足函数运算法则了。
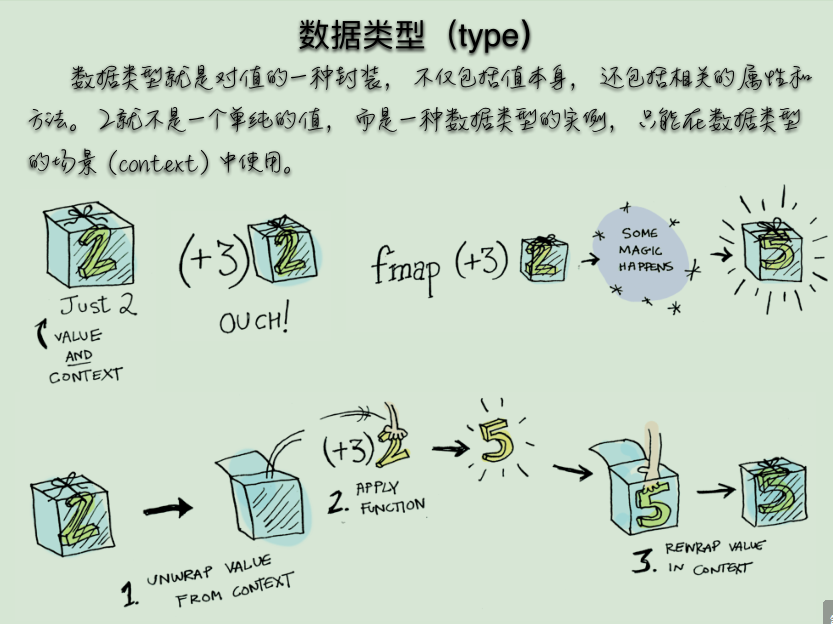
# 函子的概念
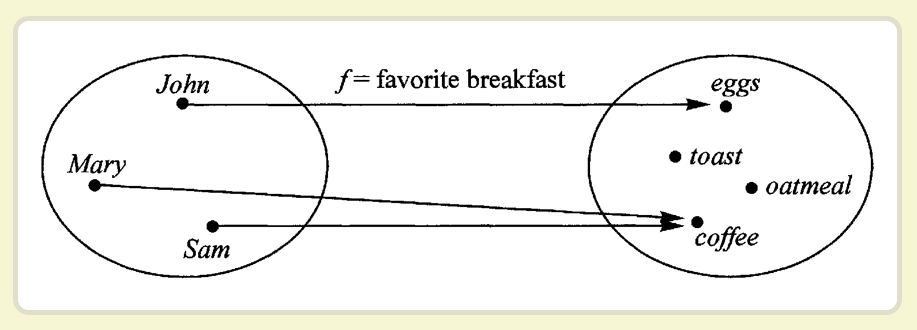
- 函数不仅可以用于同一个范畴之中值的转换,还可以用于将 一个范畴转成另一个范畴。这就涉及到了函子(Functor)。
- 函子是函数式编程里面最重要的数据类型,也是基本的运算
单位和功能单位。它首先是一种范畴,也就是说,是一个容
器,包含了值和变形关系。比较特殊的是,它的变形关系可
以依次作用于每一个值,将当前容器变形成另一个容器。
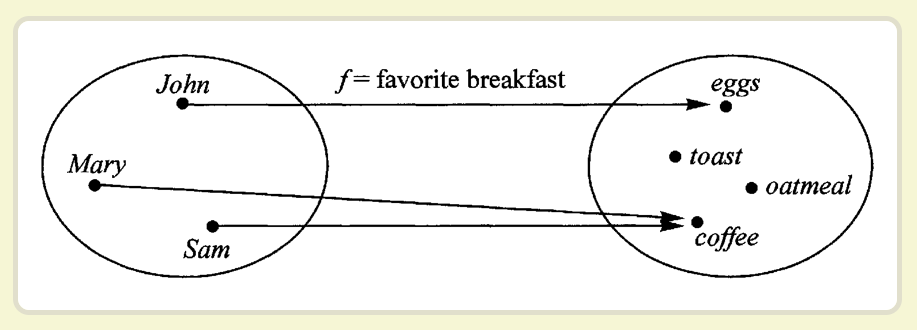
# 容器、Functor(函子)
- $(...) 返回的对象并不是一个原生的 DOM 对象,而是对于原生对 象的一种封装,这在某种意义上就是一个“容器”(但它并不函数 式)。
- Functor(函子)遵守一些特定规则的容器类型。
- Functor 是一个对于函数调用的抽象,我们赋予容器自己去调用 函数的能力。把东西装进一个容器,只留出一个接口 map 给容 器外的函数,map 一个函数时,我们让容器自己来运行这个函 数,这样容器就可以自由地选择何时何地如何操作这个函数,以 致于拥有惰性求值、错误处理、异步调用等等非常牛掰的特性。
# 函子的代码实现
var Container = function(x) {
this.__value = x;
}
//函数式编程一般约定,函子有一个of方法
Container.of = x => new Container(x);
//Container.of(‘abcd’);
//一般约定,函子的标志就是容器具有map方法。该方法将容器
里面的每一个值,映射到另一个容器。
Container.prototype.map = function(f){
return Container.of(f(this.__value))
}
Container.of(3)
.map(x => x + 1) //结果 Container(4)
.map(x => 'Result is ' + x); //结果 Container('Result is 4')
(new Functor('flamethrowers')).map(function(s) {
return s.toUpperCase();
});
// Functor('FLAMETHROWERS')
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# of方法
你可能注意到了,上面生成新的函子的时候,用了new命令。这实在太不像函数式编程了,因为new命令是面向对象编程的标志。
函数式编程一般约定,函子有一个of方法,用来生成新的容器。
下面就用of方法替换掉new。
Functor.of = function(val) {
return new Functor(val);
};
2
3
4
前面的例子就可以改成下面这样。
Functor.of(2).map(function (two) {
return two + 2;
});
// Functor(4)
2
3
4
# map方法
一般约定,函子的标志就是容器具有map方法。该方法将容器 里面的每一个值,映射到另一个容器。
说的更细致点就是:函子本身具有对外接口(map方法),各种函数就是运算符,通过接口接入容器,引发容器里面的值的变形。
因此,学习函数式编程,实际上就是学习函子的各种运算。由于可以把运算方法封装在函子里面,所以又衍生出各种不同类型的函子,有多少种运算,就有多少种函子。函数式编程就变成了运用不同的函子,解决实际问题。
(new Functor(2)).map(function (two) {
return two + 2;
});
// Functor(4)
2
3
4
# Maybe 函子(if)
函子接受各种函数,处理容器内部的值。这里就有一个问题,容器内部的值可能是一个空值(比如null),而外部函数未必有处理空值的机制,如果传入空值,很可能就会出错。
Functor.of(null).map(function (s) {
return s.toUpperCase();
});
// TypeError
class Maybe extends Functor {
map(f) {
return this.val ? Maybe.of(f(this.val)) : Maybe.of(null);
}
}
Maybe.of(null).map(function (s) {
return s.toUpperCase();
});
// Maybe(null)
//函子里面的值是null,结果小写变成大写的时候就出错了。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
Maybe 函子代码实现
//有了 Maybe 函子,处理空值就不会出错了。
var Maybe = function(x) {
this.__value = x;
}
Maybe.of = function(x) {
return new Maybe(x);
}
Maybe.prototype.map = function(f) {
return this.isNothing() ? Maybe.of(null) : Maybe.of(f(this.__value));
}
Maybe.prototype.isNothing = function() {
return (this.__value === null || this.__value === undefined);
}
//新的容器我们称之为 Maybe(原型来⾃自于Haskell)
2
3
4
5
6
7
8
9
10
11
12
13
14
# Either 函子(错误处理)
- .我们的容器能做的事情太少了,try/catch/throw 并不是“纯”的,因为它从外部接管了我们的函数,并且在这个函数出错时抛弃了它的返回值。
- Promise 是可以调用 catch 来集中处理错误的。
- 事实上 Either 并不只是用来做错误处理的,它表示了逻辑或,范畴学里的 coproduc。
代码实现
条件运算if...else是最常见的运算之一,函数式编程里面,使用 Either 函子表达。
Either 函子内部有两个值:左值(Left)和右值(Right)右值是正常情况下使用的 值,左值是右值不存在时使用的默认值。
class Either extends Functor {
constructor(left, right) {
this.left = left;
this.right = right;
}
map(f) {
return this.right ?
Either.of(this.left, f(this.right)) :
Either.of(f(this.left), this.right);
}
}
Either.of = function (left, right) {
return new Either(left, right);
};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
用法
var addOne = function (x) {
return x + 1;
};
Either.of(5, 6).map(addOne);
// Either(5, 7);
Either.of(1, null).map(addOne);
// Either(2, null);
2
3
4
5
6
7
8
9
Either 函子的另一个用途是代替try...catch,使用左值表示错误
function parseJSON(json) {
try {
return Either.of(null, JSON.parse(json));
} catch (e: Error) {
return Either.of(e, null);
}
}
上面代码中,左值为空,就表示没有出错,否则左值会包含一个错误对象e。一般来说,所有可能出错的运算,都可以返回一个 Either 函子。
2
3
4
5
6
7
8
代替try...catch原因
var Left = function(x) {
this.__value = x;
}
var Right = function(x) {
this.__value = x;
}
Left.of = function(x) {
return new Left(x);
}
Right.of = function(x) {
return new Right(x);
}
// 这⾥不同!!!
Left.prototype.map = function(f) {
return this;
}
Right.prototype.map = function(f) {
return Right.of(f(this.__value));
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
Left 和 Right 唯一的区别就在于 map 方法的实 现,Right.map 的行为和我们之前提到的 map 函数一 样。但是 Left.map 就很不同了:它不会对容器做任 何事情,只是很简单地把这个容器拿进来又扔出 去。这个特性意味着,Left 可以用来传递一个错误 消息
Either函子应用
var getAge = user => user.age ? Right.of(user.age) :
Left.of("ERROR!");
getAge({name: 'stark', age: '21'}).map(age => 'Age is ' + age);
//=> Right('Age is 21')
getAge({name: 'stark'}).map(age => 'Age is ' + age);
//=> Left('ERROR!')
2
3
4
5
6
Left 可以让调用链中任意一环的错误立刻返回到调用链的尾 部,这给我们错误处理带来了很大的方便,再也不用一层又一 层的 try/catch
# AP函子
函子里面包含的值,完全可能是函数。我们可以想象 这样一种情况,一个函子的值是数值,另一个函子的值 是函数。
function addTwo(x) {
return x + 2;
}
const A = Functor.of(2);
const B = Functor.of(addTwo)
2
3
4
5
6
上面代码中,函子A内部的值是2,函子B内部的值是函数addTwo。
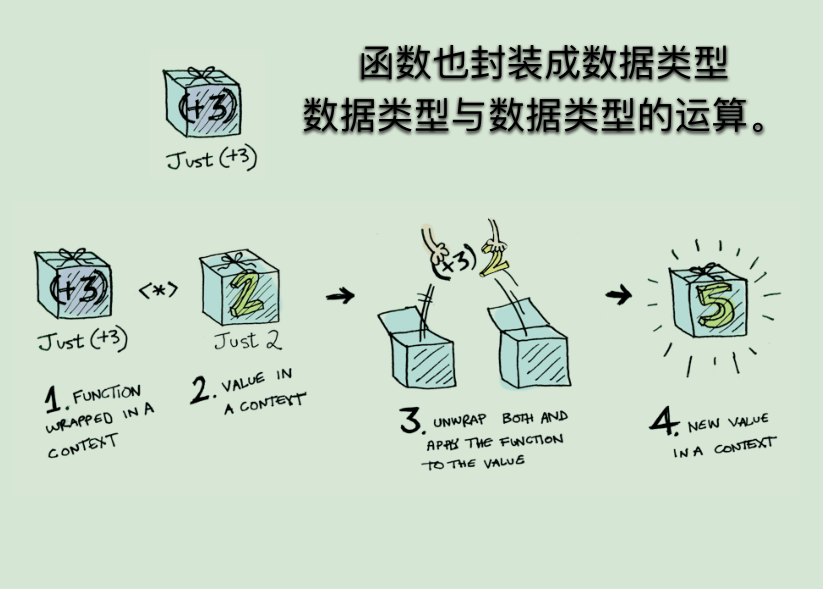
有时,我们想让函子B内部的函数,可以使用函子A内部的值进行运算。这时就需要用到 ap 函子。
ap 是 applicative(应用)的缩写。凡是部署了ap方法的函子,就是 ap 函子。
class Ap extends Functor {
ap(F) {
return Ap.of(this.val(F.val));
}
}
2
3
4
5
注意,ap方法的参数不是函数,而是另一个函子。
因此,前面例子可以写成下面的形式。
Ap.of(addTwo).ap(Functor.of(2))
// Ap(4)
2
ap 函子的意义在于,对于那些多参数的函数,就可以从多个容器之中取值,实现函子的链式操作。
function add(x) {
return function (y) {
return x + y;
};
}
Ap.of(add).ap(Maybe.of(2)).ap(Maybe.of(3));
// Ap(5)
2
3
4
5
6
7
8
上面代码中,函数add是柯里化以后的形式,一共需要两个参数。通过 ap 函子,我们就可以实现从两个容器之中取值。它还有另外一种写法。
Ap.of(add(2)).ap(Maybe.of(3));
# IO 操作
- 1.真正的程序总要去接触肮脏的世界。
function readLocalStorage(){
return window.localStorage;
}
2
3
2.IO 跟前面那几个 Functor 不同的地方在于,它的 __value 是一个函数。
它把不纯的操作(比如 IO、网络请求、DOM)包裹到一个函数内,从而 延迟这个操作的执行。所以我们认为,IO 包含的是被包裹的操作的返回 值.3.IO其实也算是惰性求值
4.IO负责了调用链积累了很多很多不纯的操作,带来的复杂性和不可维 护性
Monad 函子的重要应用,就是实现 I/O (输入输出)操作。
I/O 是不纯的操作,普通的函数式编程没法做,这时就需要把 IO 操作写成Monad函子,通过它来完成。
var fs = require('fs');
var readFile = function(filename) {
return new IO(function() {
return fs.readFileSync(filename, 'utf-8');
});
};
var print = function(x) {
return new IO(function() {
console.log(x);
return x;
});
}
//读取文件和打印本身都是不纯的操作,但是readFile和print却是纯函数,因为它们总是返回 IO 函子。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
如果 IO 函子是一个Monad,具有flatMap方法,那么我们就可以像下面这样调用这两个函数。
readFile('./user.txt')
.flatMap(print)
2
这就是神奇的地方,上面的代码完成了不纯的操作,但是因为flatMap返回的还是一个 IO 函子,所以这个表达式是纯的。我们通过一个纯的表达式,完成带有副作用的操作,这就是 Monad 的作用。
由于返回还是 IO 函子,所以可以实现链式操作。因此,在大多数库里面,flatMap方法被改名成chain
var tail = function(x) {
return new IO(function() {
return x[x.length - 1];
});
}
readFile('./user.txt')
.flatMap(tail)
.flatMap(print)
// 等同于
readFile('./user.txt')
.chain(tail)
.chain(print)
//上面代码读取了文件user.txt,然后选取最后一行输出。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
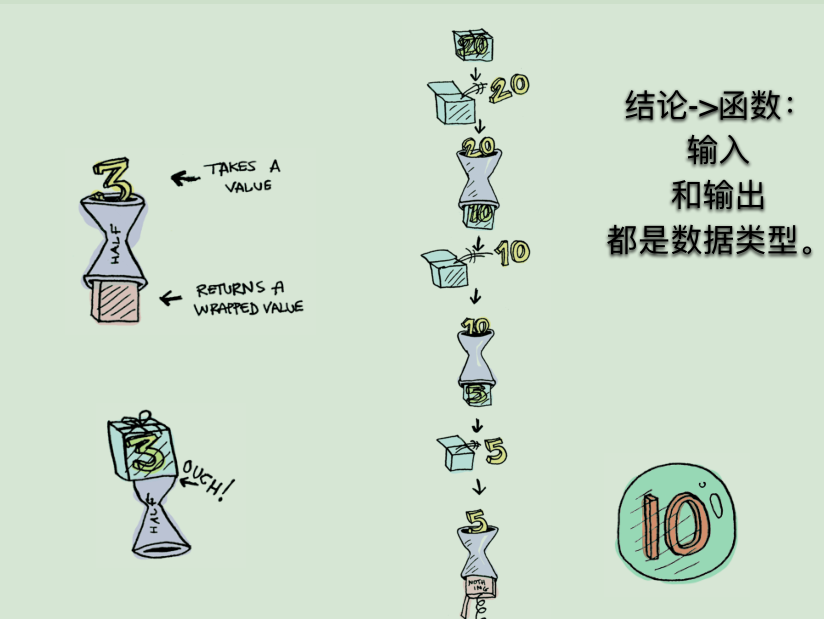
# Mound 函子
- 如何处理嵌套的 Functor 呢?(比如 Maybe(IO(42)))
- 如何处理一个由非纯的或者异步的操作序列呢?
- 1.Monad就是一种设计模式,表示将一个运算过程,通过 函数拆解成互相连接的多个步骤。你只要提供下一步运算 所需的函数,整个运算就会自动进行下去。
- 2.Promise 就是一种 Monad。
- 3.Monad 让我们避开了嵌套地狱,可以轻松地进行深度嵌 套的函数式编程,比如IO和其它异步任务。
- 4.用IO集成Monad
函子是一个容器,可以包含任何值。函子之中再包含一个函子,也是完全合法的。但是,这样就会出现多层嵌套的函子。
//多层嵌套的函子
Maybe.of(
Maybe.of(
Maybe.of({name: 'Mulburry', number: 8402})
)
)
2
3
4
5
6
//mound函子处理
class Monad extends Functor {
join() {
return this.val;
}
flatMap(f) {
return this.map(f).join();
}
}
2
3
4
5
6
7
8
9
Monad 函子的作⽤用是,总是返回一个单层的函⼦子。它有一个flatMap方法,与map方 法作⽤相同,唯⼀的区别是如果生成了了一个嵌套函子,它会取出后者内部的值,保证返 回的永远是一个单层的容器,不会出现嵌套的情况。如果函数f返回的是一个函子,那么this.map(f)就会生成一个嵌套的函子。所以,join方法保证了了flatMap方法总是返回一个单层的函⼦。这意味着嵌套的函⼦会被铺平(flatten)。
# 当下函数式编程最热的库
- RxJS
- cycleJS
- lodashJS、lazy(惰性求值)
- underscoreJS
- ramdajs
RxJS
响应式编程是继承自函数式编程,声明式的,不可变的,没有副作用的是函数式编程的三大护法。其中不可变武功最高深。一直使用面向对象范式编程的我们,习惯了用变量存储和追踪程序的状态。RxJS从函数式编程范式中借鉴了很多东西,比如链式函数调用,惰性求值等等。
在函数中与函数作用域之外的一切事物有交互的就产生了副作用。比如读写文件,在控制台打印语句,修改页面元素的css等等。在RxJS中,把副作用问题推给了订阅者来解决。
Cycle.js
Cycle.js 是一个基于 Rxjs 的框架,它是一个彻彻底底的 FRP 理念的框架,和 React 一样支持 virtual DOM、JSX 语法,但现在似乎还没有看到大型的应用经验。
本质的讲,它就是在 Rxjs 的基础上加入了对 virtual DOM、容器和组件的支持,比如下面就是一个简单的『开关』按钮:
function main(sources) {
const sinks = {
DOM: sources.DOM.select('input').events('click')
.map(ev => ev.target.checked)
.startWith(false)
.map(toggled =>
<div>
<input type="checkbox" /> Toggle me
<p>{toggled ? 'ON' : 'off'}</p>
</div>
)
};
return sinks;
}
const drivers = {
DOM: makeDOMDriver('#app')
};
run(main, drivers);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
Underscore.js
Underscore 是一个 JavaScript 工具库,它提供了一整套函数式编程的实用功能,但是没有扩展任何 JavaScript 内置对象。 他解决了这个问题:“如果我面对一个空白的 HTML 页面,并希望立即开始工作,我需要什么?” 他弥补了 jQuery 没有实现的功能,同时又是 Backbone 必不可少的部分。
Underscore 提供了100多个函数,包括常用的:map、filter、invoke, 当然还有更多专业的辅助函数,如:函数绑定、JavaScript 模板功能、创建快速索引、强类型相等测试等等。
Lodash.js
lodash是一个具有一致接口、模块化、高性能等特性的JavaScript工具库,是underscore.js的fork,其最初目标也是“一致的跨浏览器行为。。。,并改善性能”。
lodash采用延迟计算,意味着我们的链式方法在显式或者隐式的value()调用之前是不会执行的,因此lodash可以进行shortcut(捷径) fusion(融合)这样的优化,通过合并链式大大降低迭代的次数,从而大大提升其执行性能。
就如同jQuery在全部函数前加全局的$一样,lodash使用全局的_来提供对工具的快速访问
var abc = function(a, b, c) {
return [a, b, c];
};
var curried = _.curry(abc);
curried(1)(2)(3);
2
3
4
5
function square(n) {
return n * n;
}
var addSquare = _.flowRight(square, _.add);
addSquare(1, 2);
// => 9
2
3
4
5
6
Ramdajs
ramda是一个非常优秀的js工具库,跟同类比 更函数式主要体现在以下几个原则
- ramda里面的提供的函数全部都是curry的 意味着函数没有默认参数可选参数从而减轻认知函数的难度。
- ramda推崇pointfree简单的说是使用简单函数组合实现一个复杂功能,而不是单独写一个函数操作临时变量。
- ramda有个非常好用的参数占位符 R._ 大大减轻了函数在pointfree过程中参数位置的问题相比underscore/lodash 感觉要干净很多。
# 函数式编程的实际应用场景
# 易调试、热部署、并发
1.函数式编程中的每个符号都是 const 的,于是没有什么函数会有副作用。谁也不能在运行时修改任何东西,也没有函数可以修改在它的作用域之外修改什么值给其他函数继续使用。这意味着决定函数执行结果的唯一因素就是它的返回值,而影响其返回值的唯一因素就是它的参数。
2.函数式编程不需要考虑”死锁"(deadlock),因为它不修改变量,所以根本不存在"锁"线程的问题。不必担心一个线程的数据,被另一个线程修改,所以可以很放心地把工作分摊到多个线程,部署"并发编程"(concurrency)。
3.函数式编程中所有状态就是传给函数的参数,而参数都是储存在栈上的。这一特性让软件的热部署变得十分简单。只要比较一下正在运行的代码以及新的代码获得一个diff,然后用这个diff更新现有的代码,新代码的热部署就完成了。
# 单元测试
严格函数式编程的每一个符号都是对直接量或者表达式结果的引用,没有函数产生副作用。因为从未在某个地方修改过值,也没有函数修改过在其作用域之外的量并被其他函数使用(如类成员或全局变量)。这意味着函数求值的结果只是其返回值,而惟一影响其返回值的就是函数的参数。
这是单元测试者的梦中仙境(wet dream)。对被测试程序中的每个函数,你只需在意其参数,而不必考虑函数调用顺序,不用谨慎地设置外部状态。所有要做的就是传递代表了边际情况的参数。如果程序中的每个函数都通过了单元测试,你就对这个软件的质量有了相当的自信。而命令式编程就不能这样乐观了,在 Java 或 C++ 中只检查函数的返回值还不够——我们还必须验证这个函数可能修改了的外部状态。
# 总结与补充
函数式编程不应被视为灵丹妙药。相反,它应该被视为我们现有工具箱的一个很自然的补充 —— 它带来了更高的可组合性,灵活性以及容错性。现代的JavaScript库已经开始尝试拥抱函数式编 程的概念以获取这些优势。Redux 作为一种 FLUX的变种实现,核心理念也是状态机和函数式编程。
函数对于外部状态的依赖是造成系统复杂性大大提高的主要原因
让函数尽可能地纯净
软件工程上讲『没有银弹』,函数式编程同样也不是万能的,它与烂大街的 OOP 一样,只是一种编程范式而已。很多实际应用中是很难用函数式去表达的,选择 OOP 亦或是其它编程范式或许会更简单。但我们要注意到函数式编程的核心理念, 如果说 OOP 降低复杂度是靠良好的封装、继承、多态以及接口定义的话,那么函 数式编程就是通过纯函数以及它们的组合、柯里化、Functor 等技术来降低系统复 杂度,而 React、Rxjs、Cycle.js 正是这种理念的代言。让我们一起拥抱函数式编 程,打开你程序的大门!