# 前端性能优化
# 性能优化面面谈
- 1.雅虎军规
- 2.渲染加载
- 3.⻚面加载
- 4.Node加载
- 5.慎用缓存 一个小字走天下,一个监控啥也不怕。
# 浏览器渲染过程
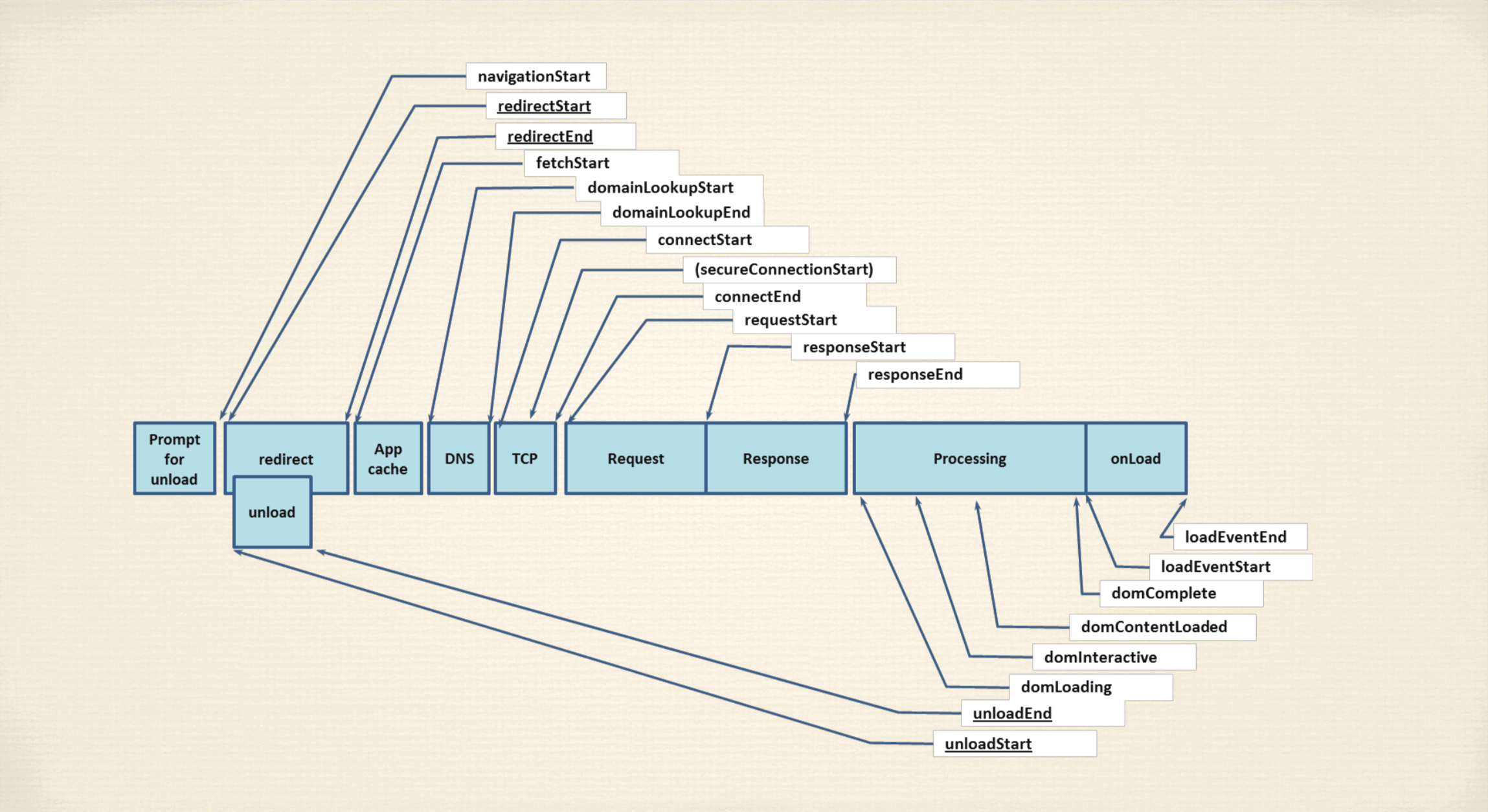
W3C专门定义的api(嵌入关键节点的API)就是浏览器渲染的标准过程。
Navigation_Timing可以帮助我们调试。
过程大体可以分为三层,如下图:
敲下回车
1.prompt forunload(提示卸载)
当新的页面要被请求的时候,把旧的页面干掉,当然还是没有去请求新的页面。
开始navigation
- redirect
首先做本地重定向(查本地是否有缓存), 并行操作unload(卸载)把上一个页面干掉,重缓存里边取新的页面。
- 3.App cache
开始拿资源
没过期从本地拿然后直接processing最后交给渲染器,显卡去。
如果缓存过期了,进行网络请求资源。走到网络层
- DNS域名解析
domainnLookupStart与domainnLookupEnd
建立TCP链接 connectstart tcp链接 secureConnectStart ssl加密链接开始
http流程 requrest与response 这块受网络状态,数据量大小,CDN技术的就近原则 响应结束
processing(资源回来了,一个html)只是一个文本文件。
把文档放到内存里,把文档解析成dom结构对象,把dom结构内的内嵌资源加载,进行请求,dom内容加载完毕后,生成渲染页面的dom的树结构,文档处理完了,开始处理事件,第一个事件是onload事件,
具体流程:
开始浏览器器渲染
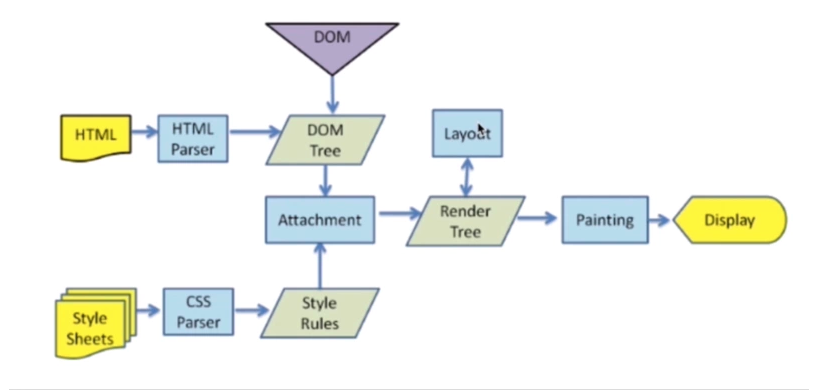 1).浏览器会解析三个东西:
1).浏览器会解析三个东西:
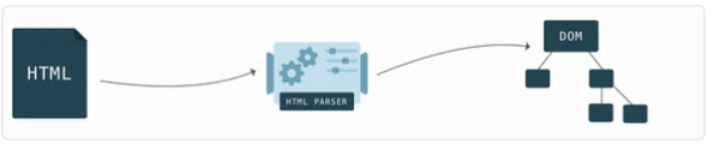
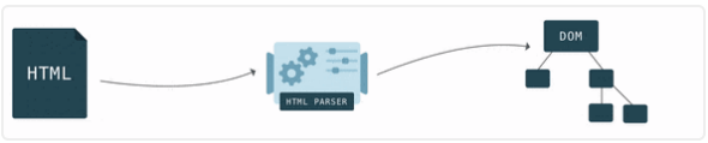
一.是HTML/SVG/XHTML,HTML字符串描述了一个页面的结构,浏览器会把HTML结构字符串解析转换DOM树形结构。
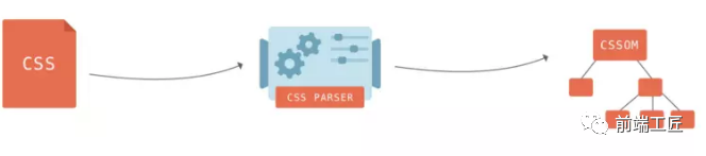
二.是CSS,解析CSS会产生CSS规则树,它和DOM结构比较像。
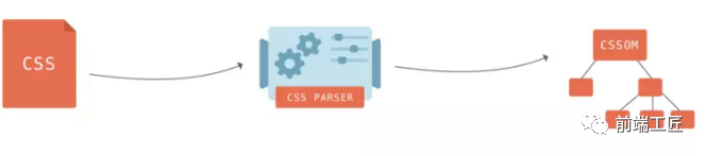
三.是Javascript脚本,等到Javascript 脚本文件加载后, 通过 DOM API 和 CSSOM API 来操作 DOM Tree 和 CSS Rule Tree。
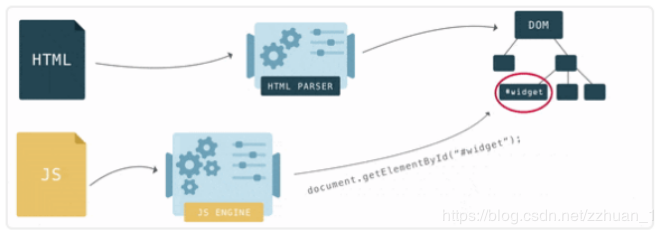
2).解析完成后,
**构建渲染树:**浏览器引擎会通过DOM Tree 和 CSS Rule Tree 来构造 (Rendering Tree/Frame Tree)
Rendering Tree 渲染树并不等同于DOM树,渲染树只会包括需要显示的节点和这些节点的样式信息。
CSS 的 Rule Tree主要是为了完成匹配并把CSS Rule附加到Rendering Tree上的每个Element(也就是每个Frame)。
布局渲染树:从根节点递归调用,计算每一个元素的大小、位置等,给出每个节点所应该在屏幕上出现的精确坐标;即计算每个Frame 的位置。
onload
开始render页面怎么显示交给显卡去操作(绘制渲染树: 遍历渲染树,使用UI后端层来绘制每个节点。)
# 性能优化启示录
# 为什么要进行性能优化?
性能优化的白皮书中:
- 57%的⽤户更在乎⽹⻚在3秒内是否完成加载。
- 52%的在线⽤户认为⽹⻚打开速度影响到他们对⽹站的忠实度。
- 每慢1秒造成⻚⾯ PV 降低11%,⽤户满意度也随之降低降低16%。
- 近半数移动⽤户因为在10秒内仍未打开⻚⾯从⽽放弃。
# 性能优化学徒工
# 雅虎军规
雅虎军规:核心:压缩合并与md5,html/css做hint,开启gzip,
HtmlHint插件配置详解
{
//标签名 小写
"tagname-lowercase": true,
//属性名称小写
"attr-lowercase": true,
//属性值使用双引号
"attr-value-double-quotes": true,
//属性值不能为空
"attr-value-not-empty": false,
//属性值不能重定义
"attr-no-duplication": true,
//html标签在头部
"doctype-first": false,
//标签配对
"tag-pair": true,
//标签自闭
"tag-self-close": false,
//id唯一
"id-unique": true,
//src非空
"src-not-empty": true,
//title必须
"title-require": false,
//alt必须
"alt-require": false,
//<!DOCTYPE>检查
"doctype-html5": false,
//文件内部样式禁止
"style-disabled": false,
//内联css机制
"inline-style-disabled": false,
//内联js禁止
"inline-script-disabled": false,
//属性特殊字符检查
"attr-unsafe-chars": false,
//头部js文件检查
"head-script-disabled": false
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
csslint插件配置详解
cssCheckOptions: {
//是否检测 !important
"important": false,
//是否允许 .bar.foo 这种两个连在一起的选择器
//未知属性检测
"known-properties": true,
//重复属性检测
"duplicate-properties": true,
//border-box 和 box-sizing检测
"box-sizing": false,
//width、height 与 border padding值一起使用时 发出警告
"box-model": false,
//display与一些其他值不能同时使用
//如 inline 不能与height同时使用 block不能使用 vertical-align table-*不能使用float
"display-property-grouping":true,
//不允许使用重复的背景图片 如果是精灵图 背景图在一个公共的类里引用 其他类用于调整位置
"duplicate-background-images":true,
//gradient 这种需要跨浏览器兼容的属性应该写在一起 避免漏改
"gradients":true,
//rgba hsl hsla这种类型的颜色会提出警告
"fallback-colors":true,
//font-size的声明不应该超过10条
"font-sizes":false,
//@font-face 这种外部字体规则不要引入太多
"font-faces":false,
//float条数超过10条时,警告
"floats":false,
//以*开头的属性检测 如 *width 检测到会报错
"star-property-hack":false,
//以_开头的属性检测
"underscore-property-hack":false,
//若有 outline:0 或 outline:none的情况并且选择器没有:focus伪类 警告
//或者选择器有:focus伪类 但是只有outline一条属性 警告
"outline-none":false,
//不允许导入css @import url(more.css);
"import":true,
//id选择器不要放在头部 例如 #head a{}这种 应该单独使用 因为css解析从右向左解析,这样反而降低了效率
"ids":false,
//h1-h6应该在头部定义 而不能再子类中再次定义 例如.box h3 {font-weight: normal;}是不行的
//.item:hover h3 { font-weight: bold; } 也是不行的 正确的是 h3{font-weight:normal}
"qualified-headings":false,
//如果你把 margin的top bottom left right都定义一遍就警告你!╭(╯^╰)╮ 如果只定义了其中1~2个不会警告
//正确食用 margin:20px 10px 5px 11px;
"shorthand":true,
//text-indent不能使用负值 除非同属性direction:ltr一起出现
"text-indent":false,
//h1-h6 只应该被定义一次 伪类不算
"unique-headings":false,
//若*选择器 是key选择器的话(最右边那个) 警告
"universal-selector":false,
//类似于[type=text]的选择器作为key选择器的时候 浏览器会先把所有的节点匹配 然后去检查他们的type属性会降低效率
"unqualified-attributes":false,
//不能只有前缀属性,没有通用属性 -moz-border-radius 并且通用属性必须在最后
"vendor-prefix":false,
//不允许 0px 0% 0em等
"zero-units":true
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
# 使用cdn
多个cdn资源->百度首页的cookie非常大,静态资源不需要,所以换一个域名而不是没次请求的时候都会带着。网站会有并发限制,用cdn的话就不会有了。
# 网站协议
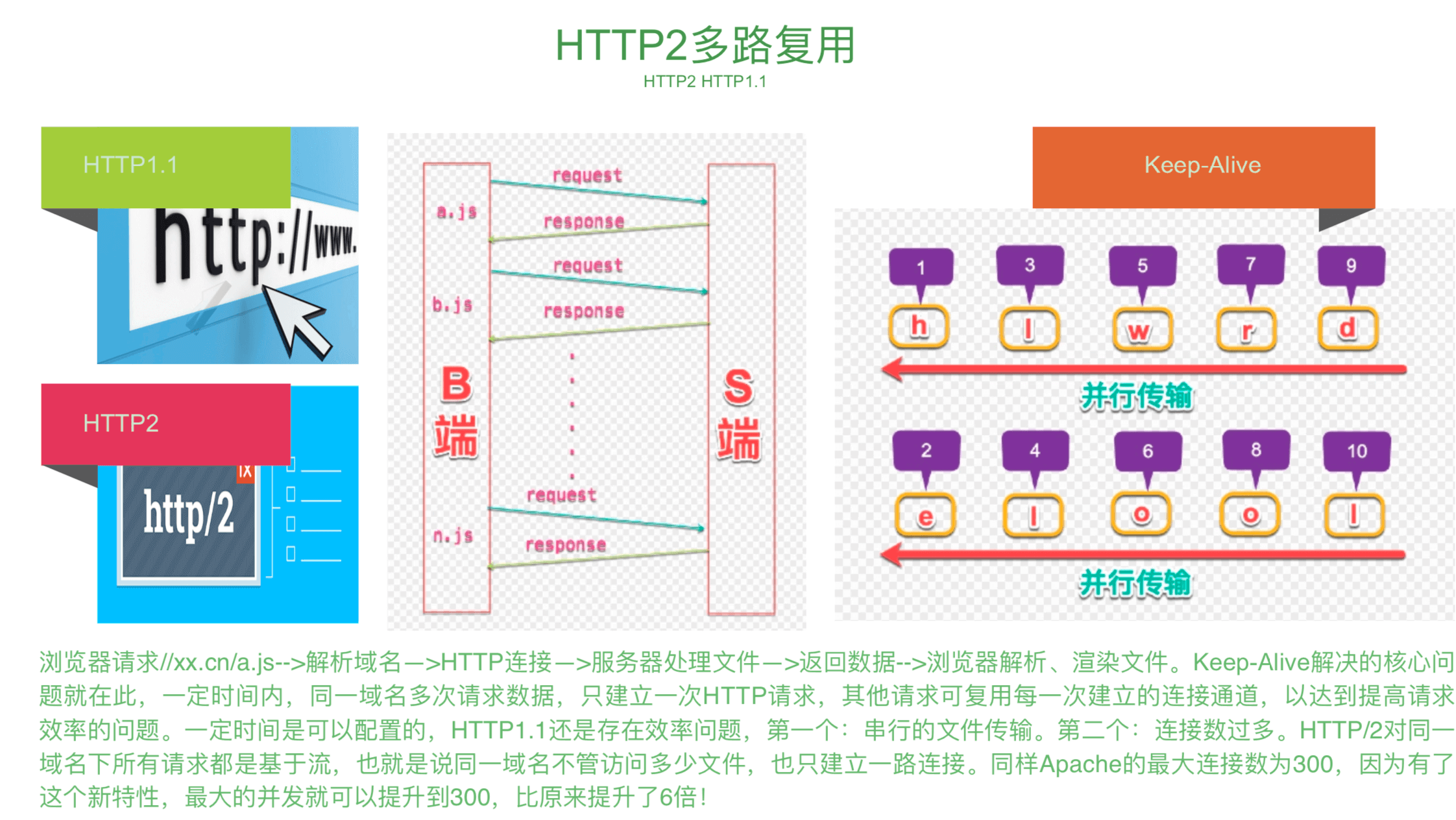
http1中的keep-live
例子:
即客户端向服务器发送一个请求信息,服务器来响应这个信息。在老的HTTP版本中,每个请求都将被创建一个新的客户端->服务器的连接,在这个连接上发送请求,然后接收请求。这样的模式有一个很大的优点就是,它很简单,很容易理解和编程实现;它也有一个很大的缺点就是,它效率很低,因此Keep-Alive被提出用来解决效率低的问题。Keep-Alive功能使客户端到服务器端的连接持续有效,当出现对服务器的后继请求时,Keep-Alive功能避免了建立或者重新建立连接。市场上 的大部分Web服务器,包括iPlanet、IIS和Apache,都支持HTTPKeep-Alive。对于提供静态内容的网站来说,这个功能通常很有用。但是,对于负担较重的网站来说,这里存在另外一个问题:虽然为客户保留打开的连 接有一定的好处,但它同样影响了性能,因为在处理暂停期间,本来可以释放的资源仍旧被占用。当Web服务器和应用服务器在同一台机器上运行时,Keep-Alive功能对资源利用的影响尤其突出。 此功能为HTTP 1.1预设的功能,HTTP 1.0加上Keep-Aliveheader也可以提供HTTP的持续作用功能。
Keep-Alive: timeout=5, max=100
timeout:过期时间5秒(对应httpd.conf里的参数是:KeepAliveTimeout),max是最多一百次请求,强制断掉连接
http2的多路复用
# memory-cache/disk-cache
webkit的资源分类主要是俩大类:主资源和派生资源
200 from memory cache
字面理解是从内存中,其实也是字面的含义,这个资源是直接从内存中拿到的,不会请求服务器一般已经加载过该资源且缓存在了内存当中,当关闭该页面时,此资源就被内存释放掉了,再次重新打开相同页面时不会出现from memory cache的情况
200 from disk cache
同上类似,此资源是从磁盘当中取出的,也是在已经在之前的某个时间加载过该资源,不会请求服务器但是此资源不会随着该页面的关闭而释放掉,因为是存在硬盘当中的,下次打开仍会from disk cache
只有当前的派生资源才会进行缓存,主文件是不缓存的,除非设置它要缓存,
memory缓存的css/js/image,就是在disk上缓存一瞬间,然后放到memory中,放memory中,放满了到disk里(主要是跟系统配置有关系)。
304 Not Modified 访问服务器,发现数据没有 更新,服务器返回此状态码。然后从缓存中读取数据。
# 三级缓存原理
- 1.先去内存看,如果有,直接加载
- 2.如果内存没有,择取硬盘获取,如果有直接加载
- 3.如果硬盘也没有,那么就进行网络请求
- 4.加载到的资源缓存到硬盘和内存
访问-> 200 -> 退出浏览器
再进来-> 200(from disk cache) -> 刷新 -> 200(from memory cache)
缓存优先级
last-modified/if-modified-since -> Etag/if-none-march -> expires/cache-Conctl
一般库文件会做一些http的缓存,因为库文件不是频繁变动,做强缓(过期时间999年),业务文件(etag/last-modified/离线缓存)
# 离线缓存
websql可以存50m,它是关系型数据库。但是读取速度缓慢,它是异步离线缓存,有可能比你的网络请求还长,他主要依赖硬件。
IndexDB是非关系型数据库。
2种方案: orm(本地持久化缓存方案)
方法一:
webpack用webpack-manifest-pugin打包一份key的js(存localstore的key,value)
过程:
1.本地缓存去取a.js
2.有激活js addscript
a.js与a.xx42.js对比
更新a.js - >a.xx44.js
a.xx44.js删除
跳回3
3.没有
a.xx44.js 放到缓存到
localstore缓存html 、js文件/css文件等,
2
3
4
5
6
7
8
9
无痕模式/急速模式 时:(什么都不会支持的时候,可以解决backet.js+localforage)
# DNS详解
DNS是Domain Name System ,域名系统
他就是用来做域名转换的
# 1.顶级域名
比如百度 baidu.com
www.baidu.com www其实是二级域名
后缀 .com/.cn/.net等
# 2.域名服务器
若干个级别
# 3.域名解析
 俩种方式:
俩种方式:
1.正向解析:域名到IP
2.反向解析ip到域名
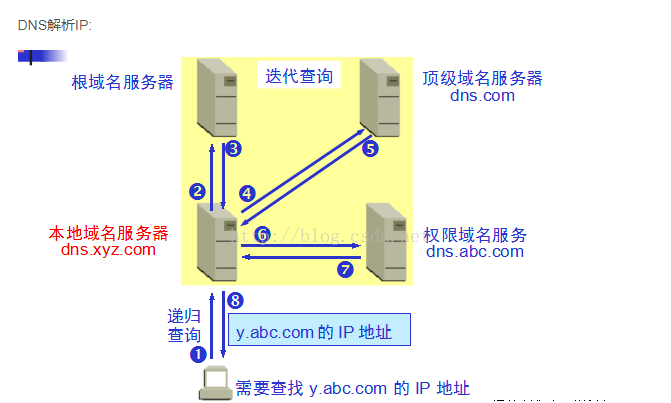
解析过程:
1.客户端到运营商服务器
2.首先查缓存
3.如果没有,去找根服务器(17台),他的作用返回后缀,告诉你通过.com去某台TLD server进行下次查询
4.TLD server(只保存着顶级域名的name server地址)解析顶级域名(.com的TLD/.cn的TLD)
5.name server查到最终的url,即解析到他的2.3.4.5....级域名
dns优化
优化是在运营商那而做一个大的缓存
注意:
阿里云是一整套全部包括了,而不是name server
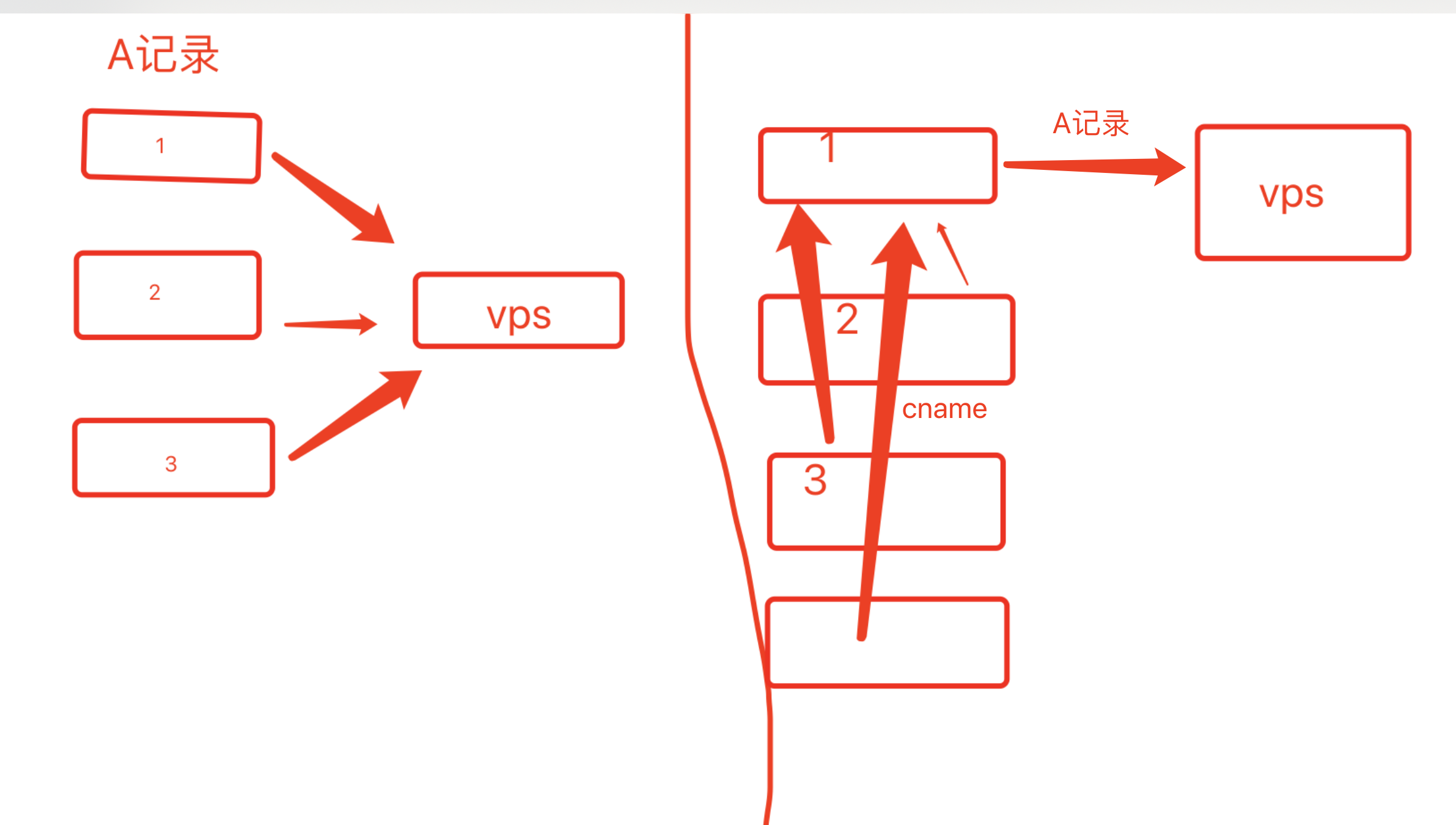
# 域名资源记录
记录类型
 注意:
注意:
- A记录主要是解析ipv4的;
- ipv6主机记录用来解析ipv6
- 切换服务器时更改,cname的妙用 正常是所有的域名指向vps即多个A记录,如果用cname的话要一个A记录其他都是cname了
# TCP三次握手与四次挥手
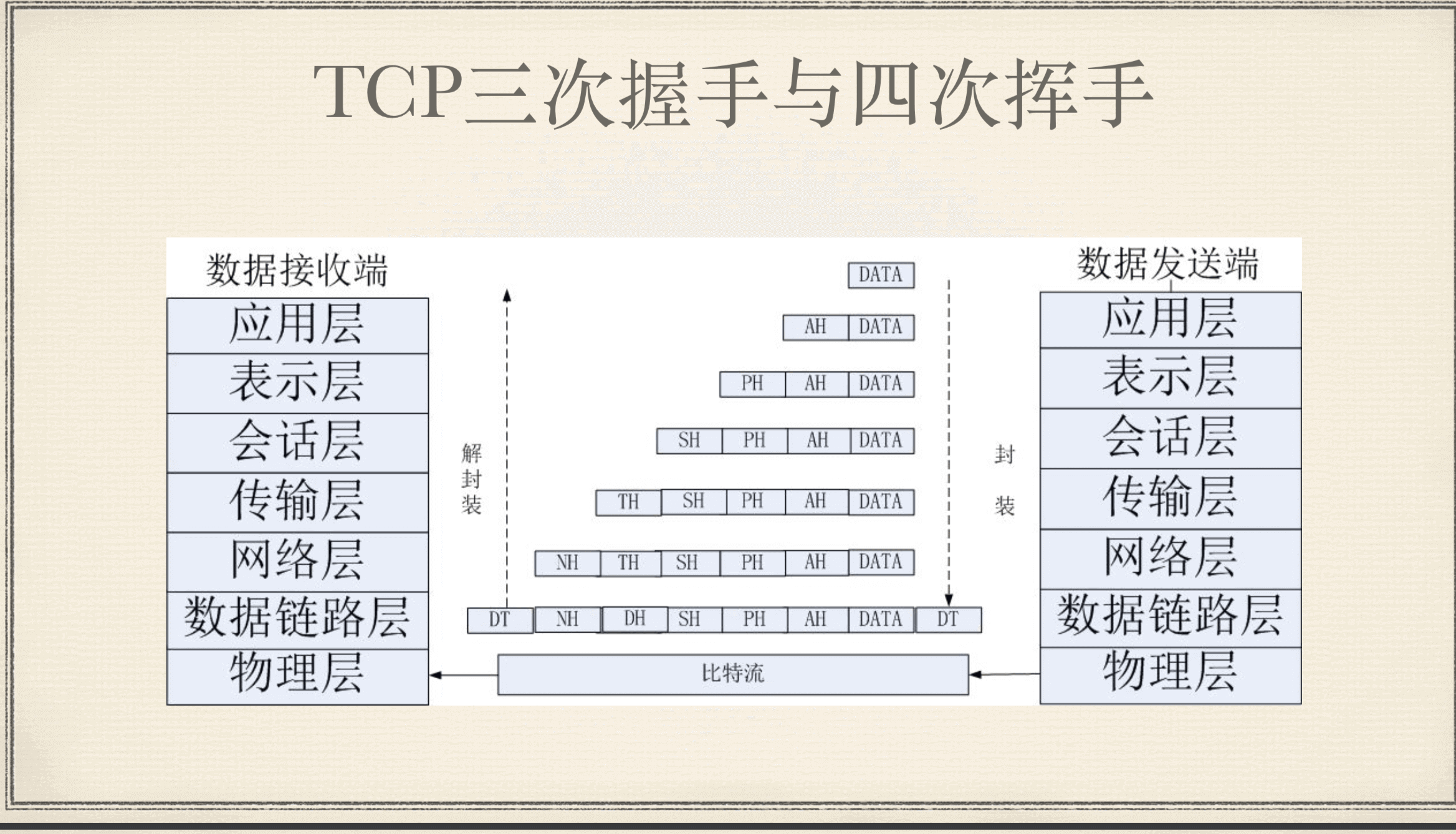
发送数据包的时候,数据包向下传递的时候逐层回家一个头,应用层->表示层->会话层 传输层 网络层 数据链路层 物理层(010101)->数据链路层 网络层 传输层 回话层 表示层 应用层
相当于加封再解封的过程。
像一个洋葱,一层一层的往外包
这个头有什么用?验证,为本层次服务,每一层都有自己的顺序号。
相当于是快递公司一样
TCP协议模型的详解
ping命令用的ICMP协议(数据报协议)
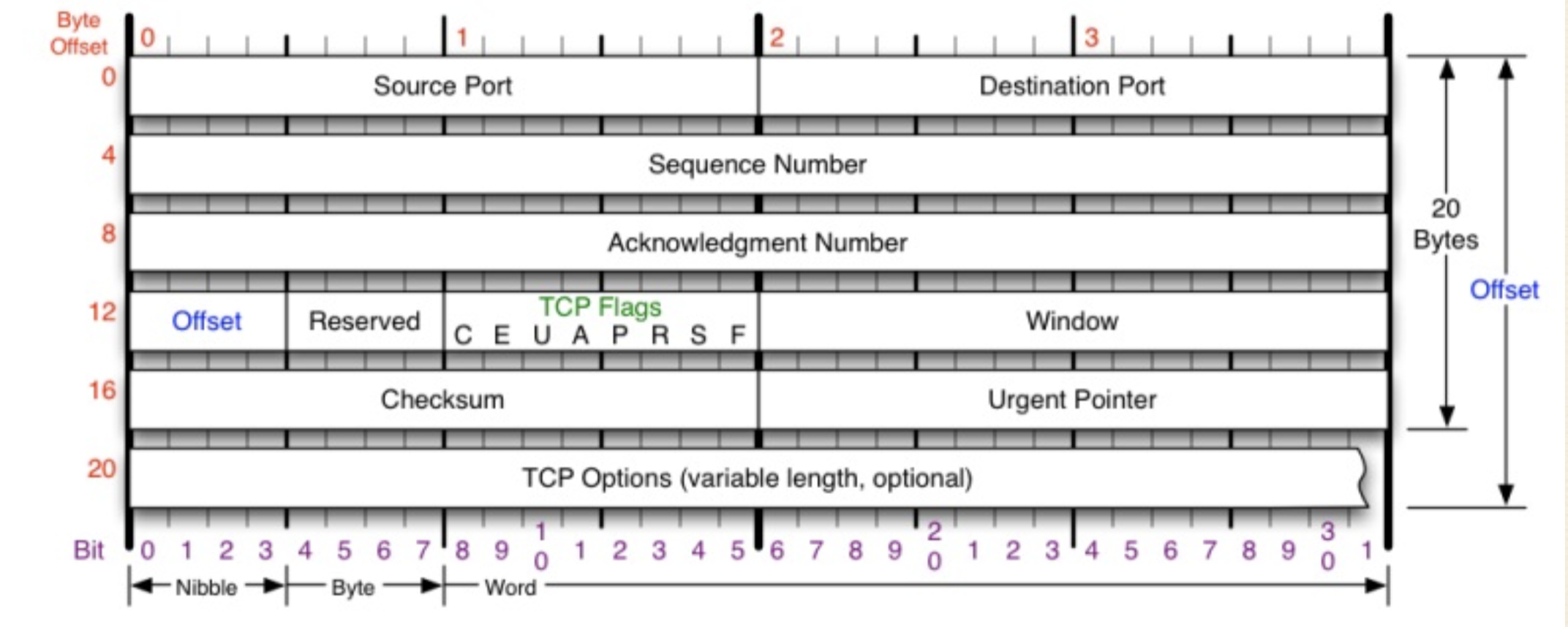 tcp协议头至少要占24个字节。这些数据都是2进制数据(因为2进制数据紧凑),http是文档。
tcp协议头至少要占24个字节。这些数据都是2进制数据(因为2进制数据紧凑),http是文档。
source:源端口,占2个字节,最大值2的16次方减1
destinationPort 服务端口(目的端口)默认端口80,必须是80端口,如果不是,tcp不认,占2个字节最大值2的16次方减1
sequence Number:顺序号(整型),为啥要编号呢?因为数据是被分割开逐个传输,如果中间丢包的话,服务器可以通过顺序号去判断是否重新补包,后边再组装,这样可以保证及时性和可靠性,占4个字节,最大值2的32次方。就向搬家一样给家具编号。
Acknowledgment Number 应答号: 这个号码可以干嘛呢? 如果丢包了 接收端发给发送端的丢包编码。
offset 偏移量(决定头的大小)
# tcp与udp的区别
tcp相当于打电话 拨号 接起电话 你喂 对方回应喂 然后说话 你说挂,看还有什么没做,他说没没了挂吧 然后挂
udp只管发,发没发到它不管,相当于广播找人。找不找的到它不管。
# tcp的三次握手与四次挥手
在通信这一块,谁发起通信谁是客户端。
发起请求和断开连接请求都是客户端发起的
双向通信
三次握手就是tcp建立链接时的通信
1.客户端发送链接请求(syn)同时发送一个seq顺序号
2.服务器发送连接请求响应客户端的连接请求(syn) 和一个顺序号seq以及一个应答号(客户端发过来的顺序号加一)是放在一个包里的
3.客户端表示收到服务器的请求发送一个应答号(服务器的顺序号加一)
4.连接成功
开始数据传输(来来回回n次)顺序号与应答号一直叠加
四次挥手就是断开连接的通信()
- 客户端发送服务情请求断开连接的包,并且询问通知服务器要断开请求,询问活干完没,一个顺序号。
- 服务器 发送一个收到请求的应答号的包,然后检查一下工作是否完成,向客户端发送一个断开确认的包,顺序号。
- 收到断开确认包后,向服务器发送断开确认的包,应答号。
双向双工通信,单向单工通信
单向:一个端只能向另一端发送,但不能接受,即一段只有发送工具,一端只有接受的功能。
双向:俩端可以互相传。
单工:数据传输只支持数据在一个方向上的传输,同时只能有一方能发送或接收信息。即:如果是双向通信的话,当一方在向另一方发送,另一方不能向对方发送数据
双工:是同时可以进行双向传输。即如果是双向通信的话,当一方在向另一方发送,另一方可以同时向对方发送数据, 例子:广播
半双工:数据传输允许数据来两个方向上传输,但是任一时刻,都只允许数据在一个方向上传播,它实际上是一种切换方向的单工通信;同一时间内,只可以有一方接收或者发送信息。 例子:手机通话
例子:
对讲机是单工双向通信;
电话是双工通信
HTTP协议 是什么工作模式呢?
- 最初的 http版本 就是1.1以下的 是单工。
- 1.1版本通过kepp alive 可以实现半双工 一般需要服务器配置开启长连接 。现在的网站用的1.1 版本 但是长连接是否可用 需要看服务器的配置 。
- Http2.0是一代http的版本 现在在试行中 很多浏览器和服务器不支持 ,是双工通信的协议 为了弥补之前的不足。 补充:
- http协议有多个版本,存在区别,截至2019.1,主流协议是http1.1
- http1.1以下版本,http连接为短连接,tcp连接发送信息等待接受信息后断开.
- http1.1 是半双工,建立长连接,出现多路复用,可先后发送多个http请求,不用等待回复,但是回复按顺序一个一个回复.(当前主流) -http2.0是全双工,一个消息发送后不用等待接受,第二个消息可以直接发送.
# CDN概念
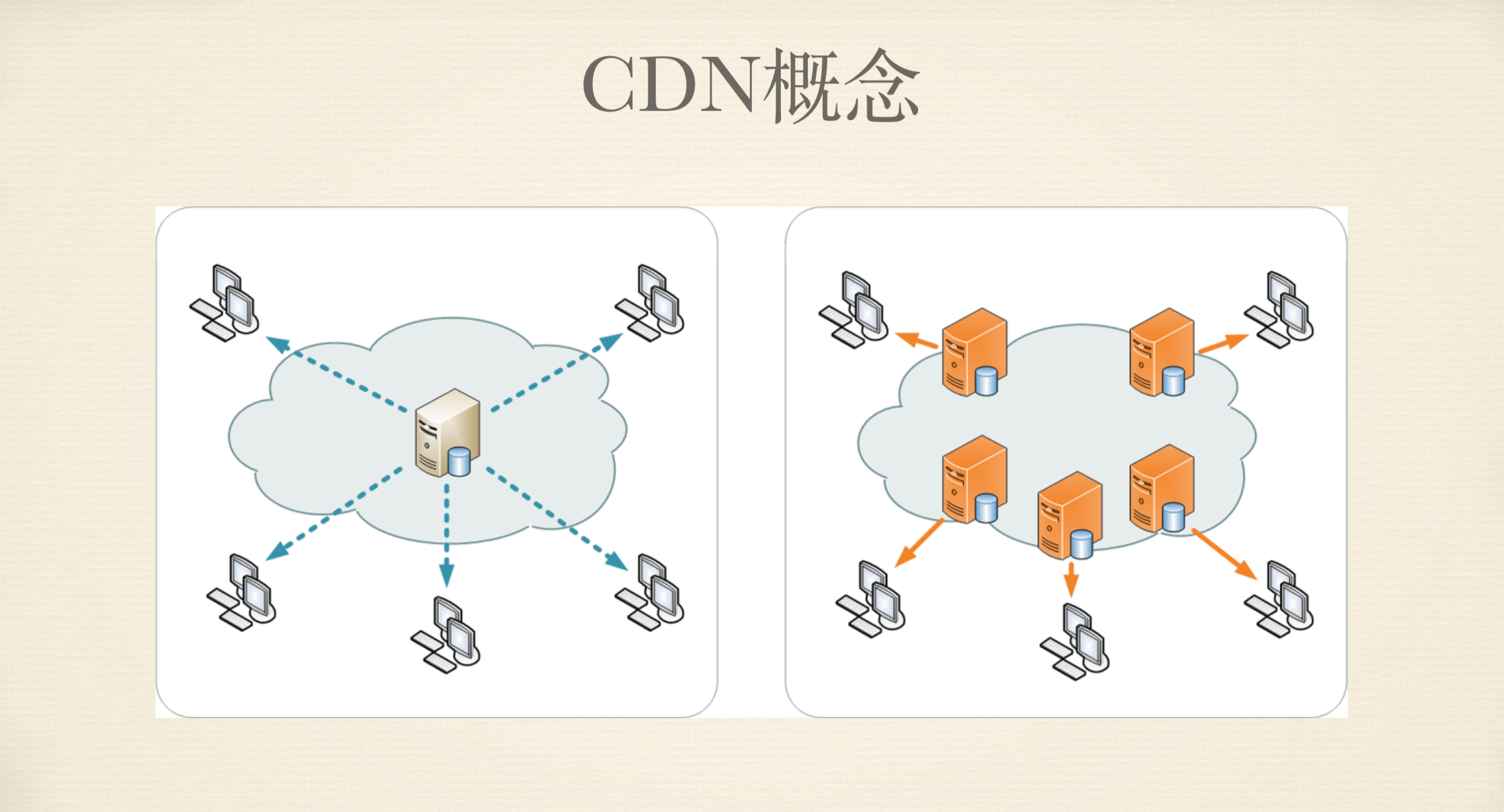
图一:集中式(传统的网络)必须从一台服务器上请求
带宽,距离,一个服务器造成延迟与服务器压力问题
图二:cdn模式(讲求近就原则)
即产生多个镜像服务器,解决了服务器压力以及延迟
CDN缓存
CDN缓存属于Cache服务器的一种。 CDN的全称是Content Delivery Network,即内容分发网络。其目的是通过在现有的Internet中增加一层新的网络架构,将网站的内容发布到最接近用户的网络"边缘",使用户可 以就近取得所需的内容,解决Internet网络拥塞状况,提高用户访问网站的响应速度。从技术上全面解决由于网络带宽小、用户访问量大、网点分布不均等 原因,解决用户访问网站的响应速度慢的根本原因。
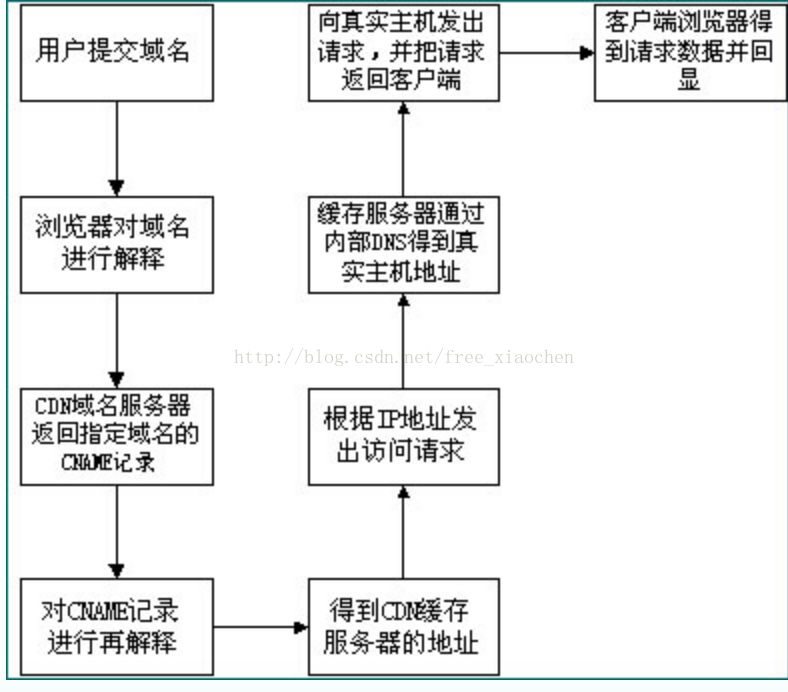
通过上图,我们可以了解到,使用了CDN缓存后的网站的访问过程为: 1)、用户向浏览器提供要访问的域名; 2)、浏览器调用域名解析库对域名进行解析,由于CDN对域名解析过程进行了调整,所以解析函数库一般得到的是该域名对应的CNAME记录,为了得到实际IP地址,浏览器需要再次对获得的CNAME域名进行解析以得到实际的IP地址;在此过程中,使用的全局负载均衡DNS解析,如根据地理位置信 息解析对应的IP地址,使得用户能就近访问。 3)、此次解析得到CDN缓存服务器的IP地址,浏览器在得到实际的IP地址以后,向缓存服务器发出访问请求; 4)、若请求文件并未修改,返回304(充当服务器的角色)。若当前文件已过期,则缓存服务器根据浏览器提供的要访问的域名,通过Cache内部专用DNS解析得到此域名的实际IP地址,再由缓存服务器向此实际IP地址提交访问请求; 5)、缓存服务器从实际IP地址得得到内容以后,一方面在本地进行保存,以备以后使用,二方面把获取的数据返回给客户端,完成数据服务过程; 6)、客户端得到由缓存服务器返回的数据以后显示出来并完成整个浏览的数据请求过程。
# http缓存机制
缓存优先级
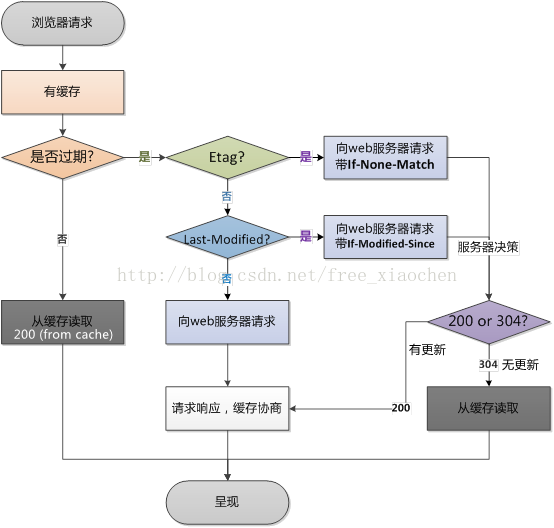
浏览器第一次请求流程图
 浏览器再次请求时
缓存会根据请求保存输出内容的副本,例如html页面,图片,文件,当下一个请求来到的时候:如果是相同的URL,缓存直接使用副本响应访问请求,而不是向源服务器再次发送请求,。
浏览器再次请求时
缓存会根据请求保存输出内容的副本,例如html页面,图片,文件,当下一个请求来到的时候:如果是相同的URL,缓存直接使用副本响应访问请求,而不是向源服务器再次发送请求,。
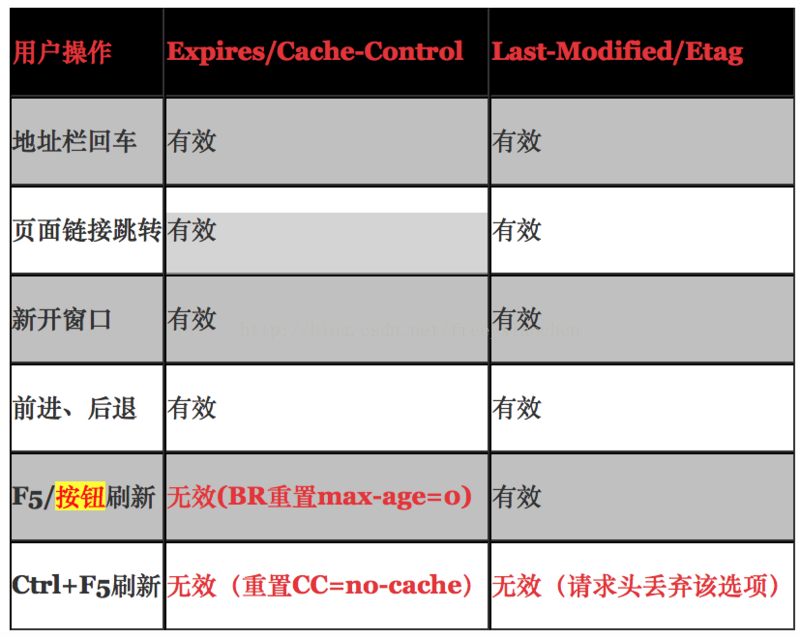 浏览器缓存行为还有用户的行为有关
浏览器缓存行为还有用户的行为有关
缓存的优点:
- 减少相应延迟,提高响应速度
- 减少网络带宽消耗

浏览器的缓存是强制缓存与对比缓存搭配起来用的
缓存分为俩大类: 强制缓存不管服务器是否要求都要缓存
对比缓存,通过与服务器对比去缓存(把缓存标记和时间确定是否要去缓存);
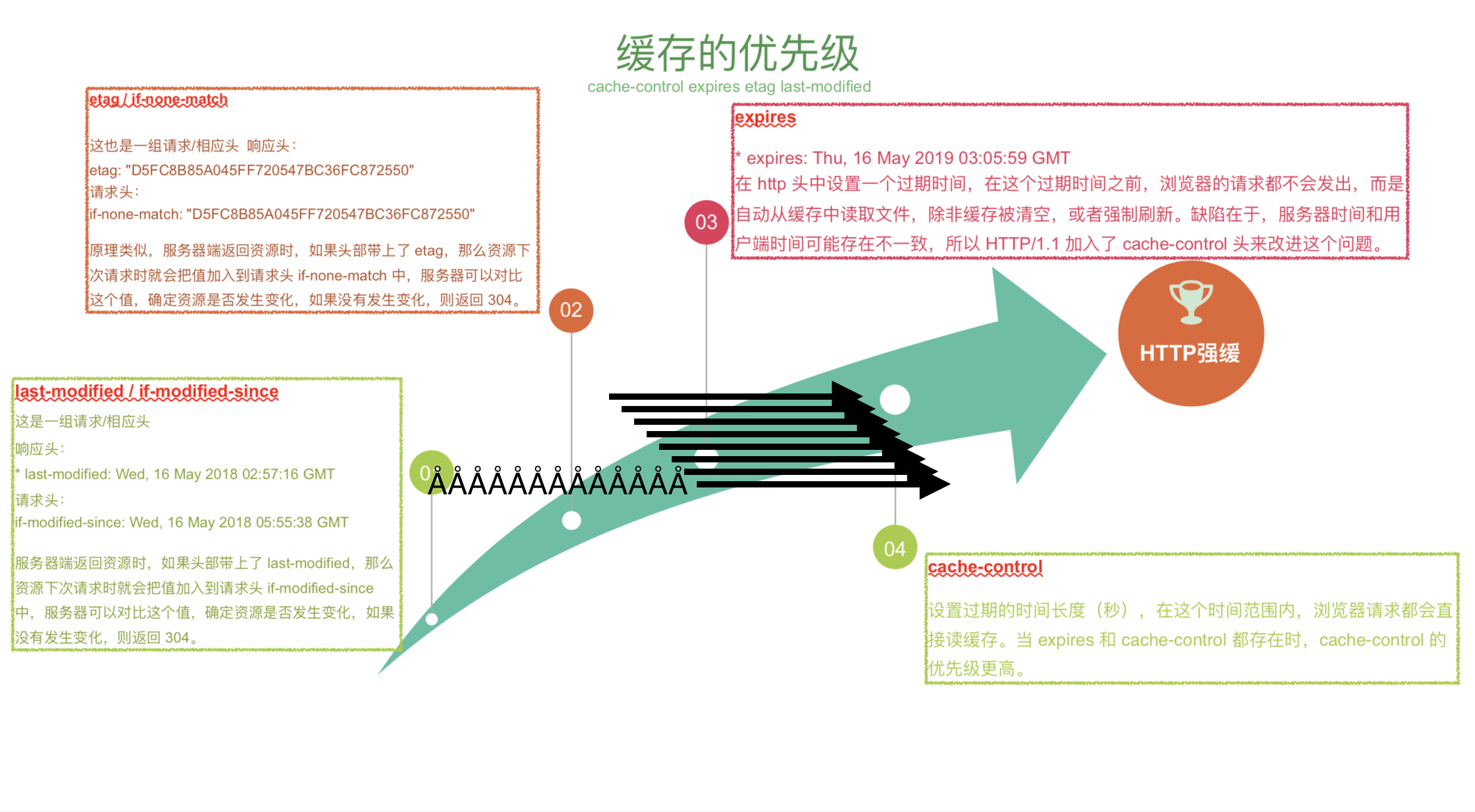
# 强制缓存
强制缓存,服务器通知浏览器一个缓存时间,在缓存时内,下次请求,直接用缓存,不在时间内,执行比较缓存策略。
对于强制缓存来说,响应header中会有两个字段来标明失效规则(Expires/Cache-Control) 使用chrome的开发者工具,可以很明显的看到对于强制缓存生效时,网络请求的情况
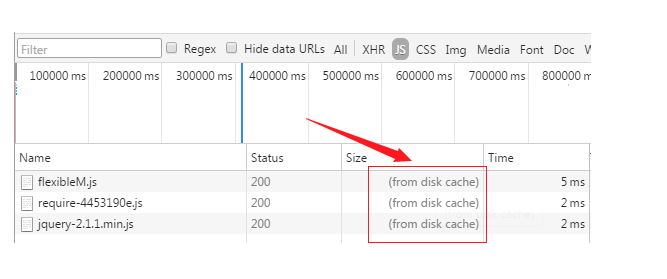
Expires
Expires的值为服务端返回的到期时间,即下一次请求时,请求时间小于服务端返回的到期时间,直接使用缓存数据。 不过Expires 是HTTP 1.0的东西,现在默认浏览器均默认使用HTTP 1.1,所以它的作用基本忽略。 另一个问题是,到期时间是由服务端生成的,但是客户端时间可能跟服务端时间有误差,这就会导致缓存命中的误差。 所以HTTP 1.1 的版本,使用Cache-Control替代。
Cache-Control
Cache-Control 是最重要的规则。常见的取值有private、public、no-cache、max-age,no-store,默认为private。
- private: 客户端可以缓存
- public: 客户端和代理服务器都可缓存(前端的同学,可以认为public和private是一样的)
- max-age=xxx: 缓存的内容将在 xxx 秒后失效
- no-cache: 需要使用对比缓存来验证缓存数据(后面介绍)
- no-store: 所有内容都不会缓存,强制缓存,对比缓存都不会触发(对于前端开发来说,缓存越多越好,so…基本上和它说886)

图中Cache-Control仅指定了max-age,所以默认为private,缓存时间为31536000秒(365天) 也就是说,在365天内再次请求这条数据,都会直接获取缓存数据库中的数据,直接使用。
# 比较缓存
- 比较缓存,顾名思义,需要进行比较判断是否可以使用缓存,也叫协商缓存,
浏览器第一次请求数据时,服务器会将缓存标识与数据一起返回给客户端,客户端将二者备份至缓存数据库中。 再次请求数据时,客户端将备份的缓存标识发送给服务器,服务器根据缓存标识进行判断,判断成功后,返回304状态码,通知客户端比较成功,可以使用缓存数据。
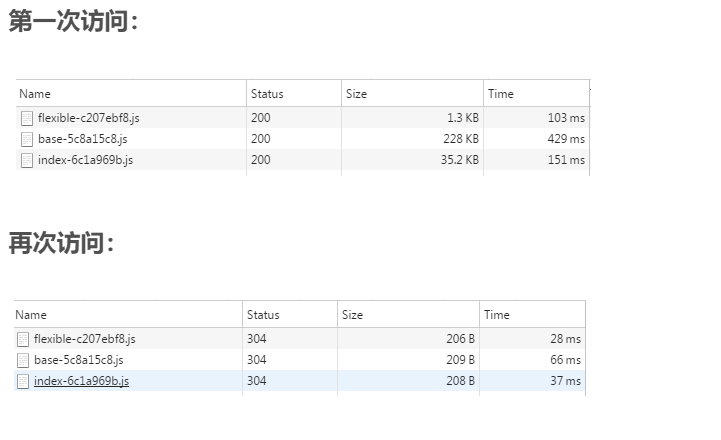
通过两图的对比,我们可以很清楚的发现,在对比缓存生效时,状态码为304,并且报文大小和请求时间大大减少。 原因是,服务端在进行标识比较后,只返回header部分,通过状态码通知客户端使用缓存,不再需要将报文主体部分返回给客户端。
对于对比缓存来说,缓存标识的传递是我们着重需要理解的,它在请求header和响应header间进行传递, 一共分为两种标识传递或者叫俩种策略,接下来,我们分开介绍
Last-Modified/If-Modified-Since策略
**Last-Modified:**服务器在响应请求时,告诉浏览器资源的最后修改时间。

- 两类缓存规则可以同时存在,强制缓存优先级高于对比缓存,也就是说,当执行强制缓存的规则时,如果缓存生效,直接使用缓存,不再执行对比缓存规则。
If-Modified-Since: 再次请求服务器时,通过此字段通知服务器上次请求时,服务器返回的资源最后修改时间。 服务器收到请求后发现有头If-Modified-Since 则与被请求资源的最后修改时间进行比对。 若资源的最后修改时间大于If-Modified-Since,说明资源又被改动过,则响应整片资源内容,返回状态码200; 若资源的最后修改时间小于或等于If-Modified-Since,说明资源无新修改,则响应HTTP 304,告知浏览器继续使用所保存的cache。

Etag/If-None-Match策略
(优先级高于Last-Modified / If-Modified-Since)
Etag: 服务器响应请求时,告诉浏览器当前资源在服务器的唯一标识(生成规则由服务器决定)

If-None-Match:
再次请求服务器时,通过此字段通知服务器客户段缓存数据的唯一标识。 服务器收到请求后发现有头If-None-Match 则与被请求资源的唯一标识进行比对, 不同,说明资源又被改动过,则响应整片资源内容,返回状态码200; 相同,说明资源无新修改,则响应HTTP 304,告知浏览器继续使用所保存的cache

# 渲染中性能优化
1.网页渲染过程
1-1.获取dom分割成多层Parse Html
1-2.对每一层计算样式结果 Pecalculate Style
1-3.为每个节点生成位置和图形的过程 **重排** Layout
1-4.将每个节点绘制并填充到图层的位图中 **重绘** Paint
1-5.绘制出来的纹理上传到GPU Composite Layers 合成层
2
3
4
5
2.大致的一个流程就是重排->重绘-> Composite Layers
3.网络分层
根元素,position,transform,半透明,滤镜,canvas,video,overflow
4.什么会让GPU参与成层(跳过重绘重排直接合成)?
webgl,css3d,video,transform,滤镜
5.cpu与gpu的相同点与不同点
相同点:俩者都有总线和外联系,有自己的缓存体系,以及数字和逻辑运算单位,诶了完成结算任务而生。
不同之处:CPU操作系统和应用程序,GPU显示相关,GPU的活CPU都能干,但是效率低。
重绘:当盒子的位置、大小以及其他属性,例如颜色、字体大小等都确定下来之后,浏览器便把这些原色都按照各自的特性绘制一遍,将内容呈现在页面上。重绘是指一个元素外观的改变所触发的浏览器行为,浏览器会根据元素的新属性重新绘制,使元素呈现新的外观。
触发重绘的条件:改变元素外观属性。如:color,box-shadow,background-color等。
重排/回流:
当渲染树中的一部分(或全部)因为元素的规模尺寸,布局,隐藏等改变而需要重新构建, 这就称为回流(reflow)。每个页面至少需要一次回流,就是在页面第一次加载的时候。
下述情况会发生重排:
- 添加或删除可见的DOM元素。
- 元素的位置、尺寸(内外边距、边框厚度、宽高等属性)改变
- 内容改变(文本改变或者图片大小改变而引起的计算值宽度和高度改变)
- 页面渲染器初始化
- 浏览器窗口尺寸改变——resize事件发生时。
js中一些方法会导致重新获取布局信息,刷新渲染队列。
- offsetTop,offsetLeft,offsetWidth,offsetHeight
- scrollTop,scrollLeft,scrollWidth,scrollHeight
- clientTop,clientLeft,clientWidth,clientHeight
- getComputedStyle(currentStyle in IE)
所以重绘未必会发生重排,但是重排一定会发生重绘。
重绘重排的代价:耗时,导致浏览器卡慢。
如何规避?
- 1.分离读写操作;
- 2.样式集中改变,即将多次改变样式属性的操作合并成一次操作
- 3.
translate属性值来替换top/left/right/bottom的切换,scale属性值替换width/height,opacity属性替换display/visibility等等 - 4.将需要多次重排的元素,position属性设为absolute或fixed,这样此元素就脱离了文档流,它的变化不会影响到其他元素。例如有动画效果的元素就最好设置为绝对定位。
- 5.在内存中多次操作节点,完成后再添加到文档中去。例如要异步获取表格数据,渲染到页面。可以先取得数据后在内存中构建整个表格的html片段,再一次性添加到文档中去,而不是循环添加每一行。
- 6.由于display属性为none的元素不在渲染树中,对隐藏的元素操作不会引发其他元素的重排。如果要对一个元素进行复杂的操作时,可以先隐藏它,操作完成后再显示。这样只在隐藏和显示时触发2次重排。
- 7.在需要经常取那些引起浏览器重排的属性值时,要缓存到变量。
# ⻚⾯加载性能优化
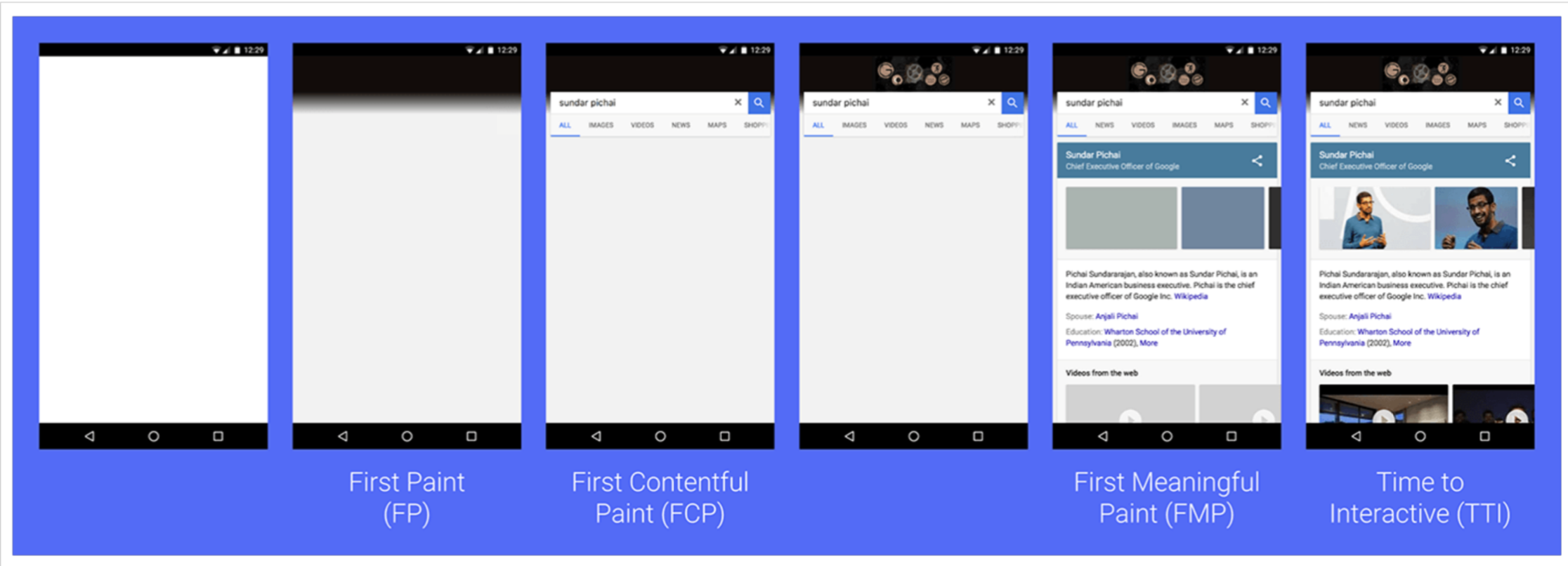
# FP/FCP/FMP/TTI四个性能指标
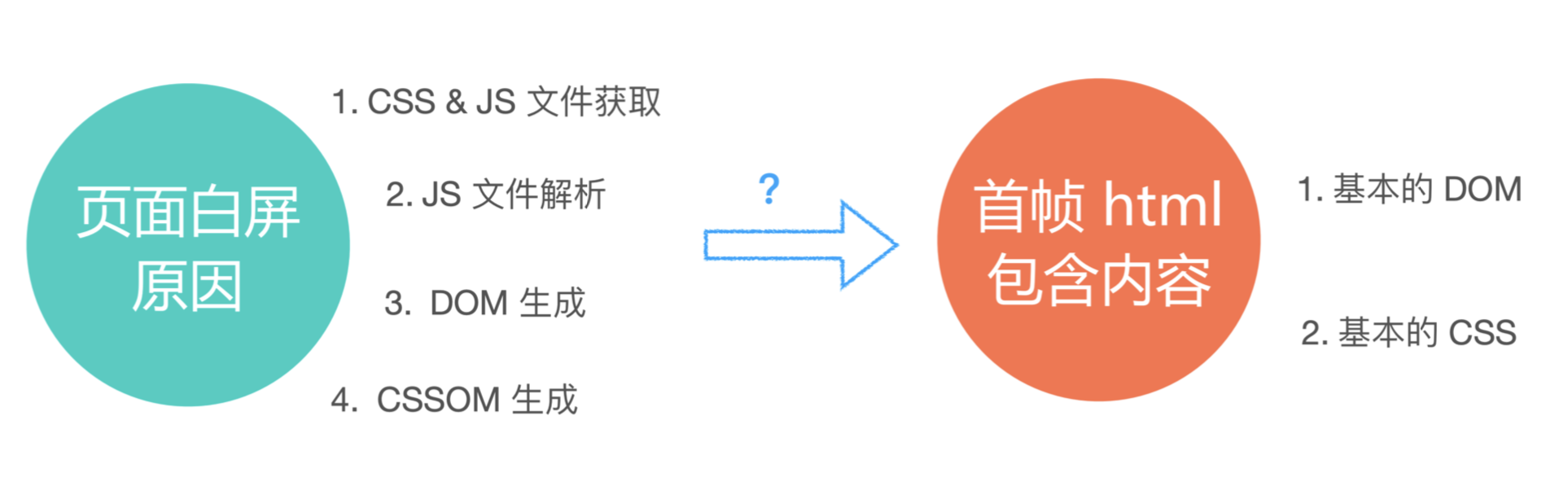
- FP:First Paint, 首次绘制(白屏时间,根节点首个div)
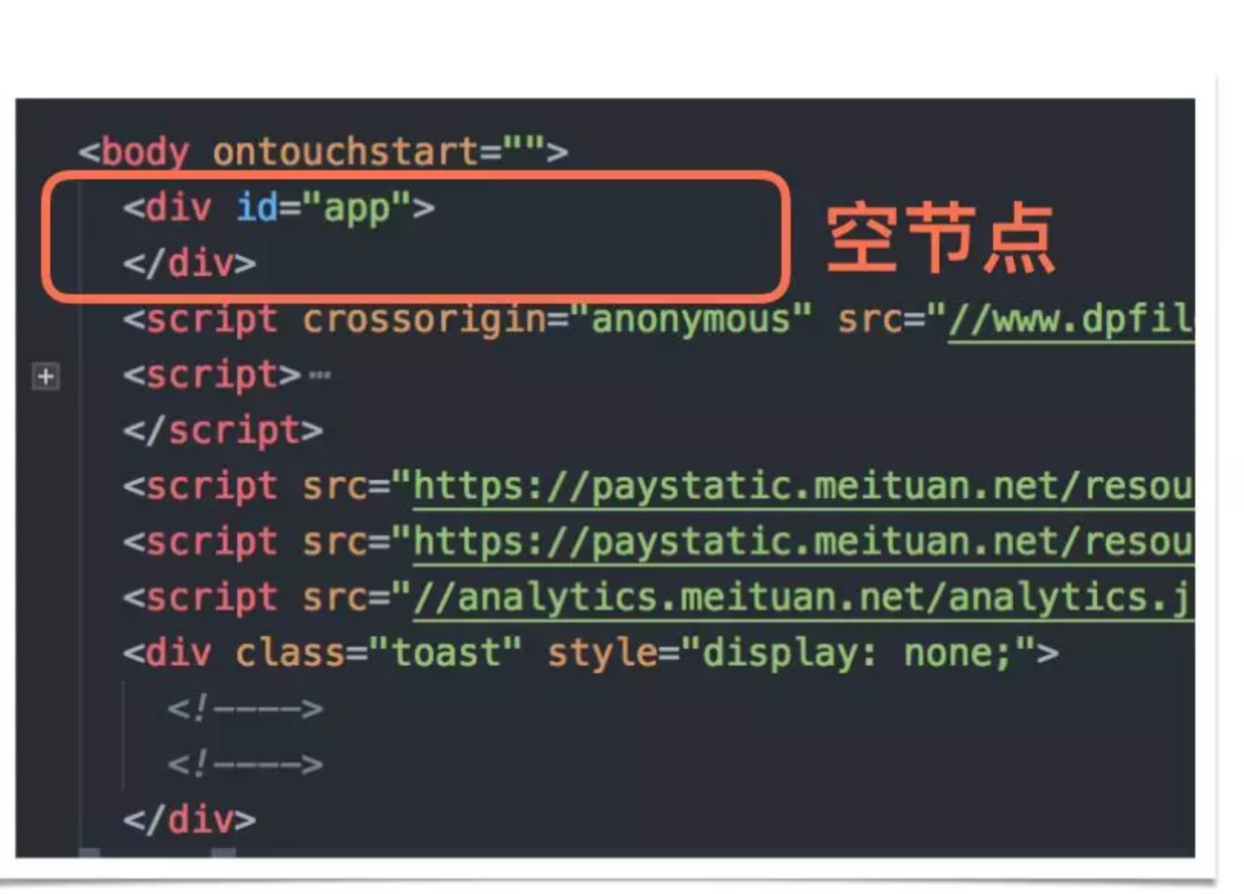
- FCP:First Contentful Paint, ⾸次有内容的绘制(包含⻚页⾯面的基本框架,但没有数据内容)
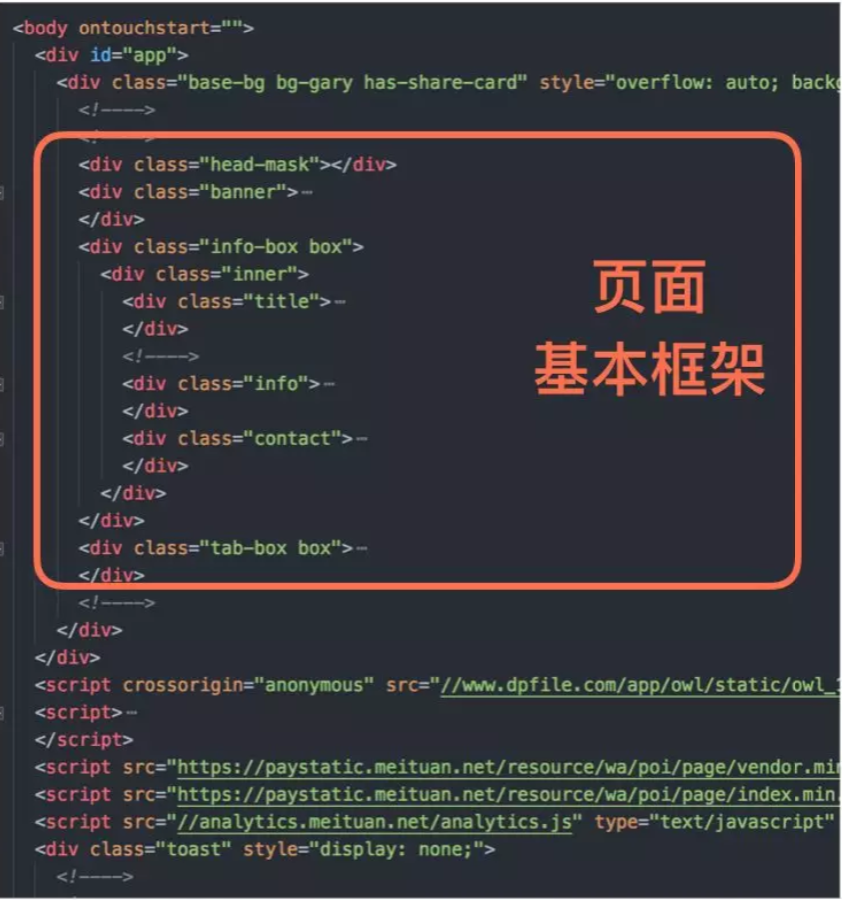
- FMP:First Meaningful Paint,⾸次有意义的绘制(包含页⾯所有元素及数据)
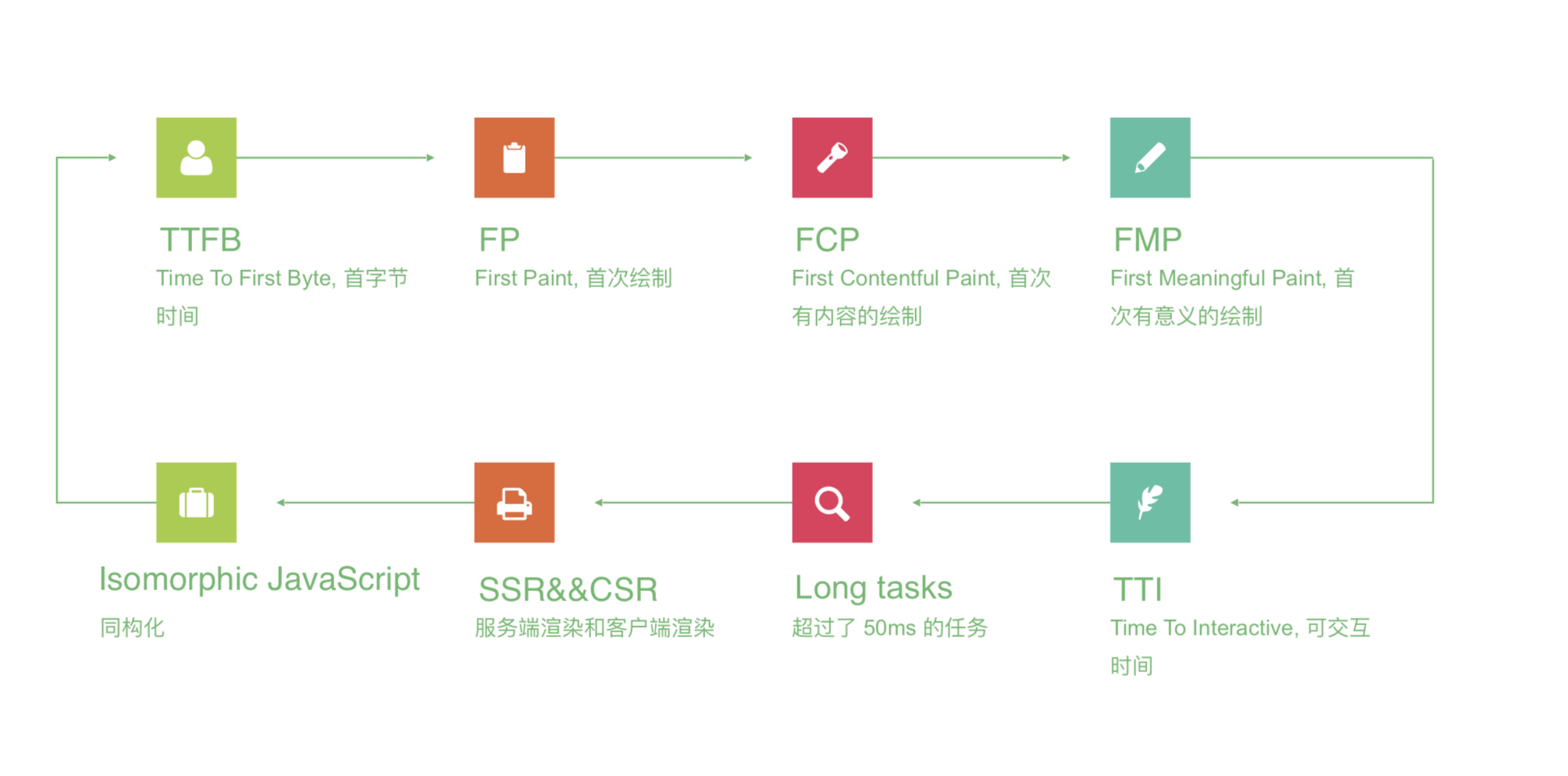
- TTI:Time To Interactive, 可交互时间
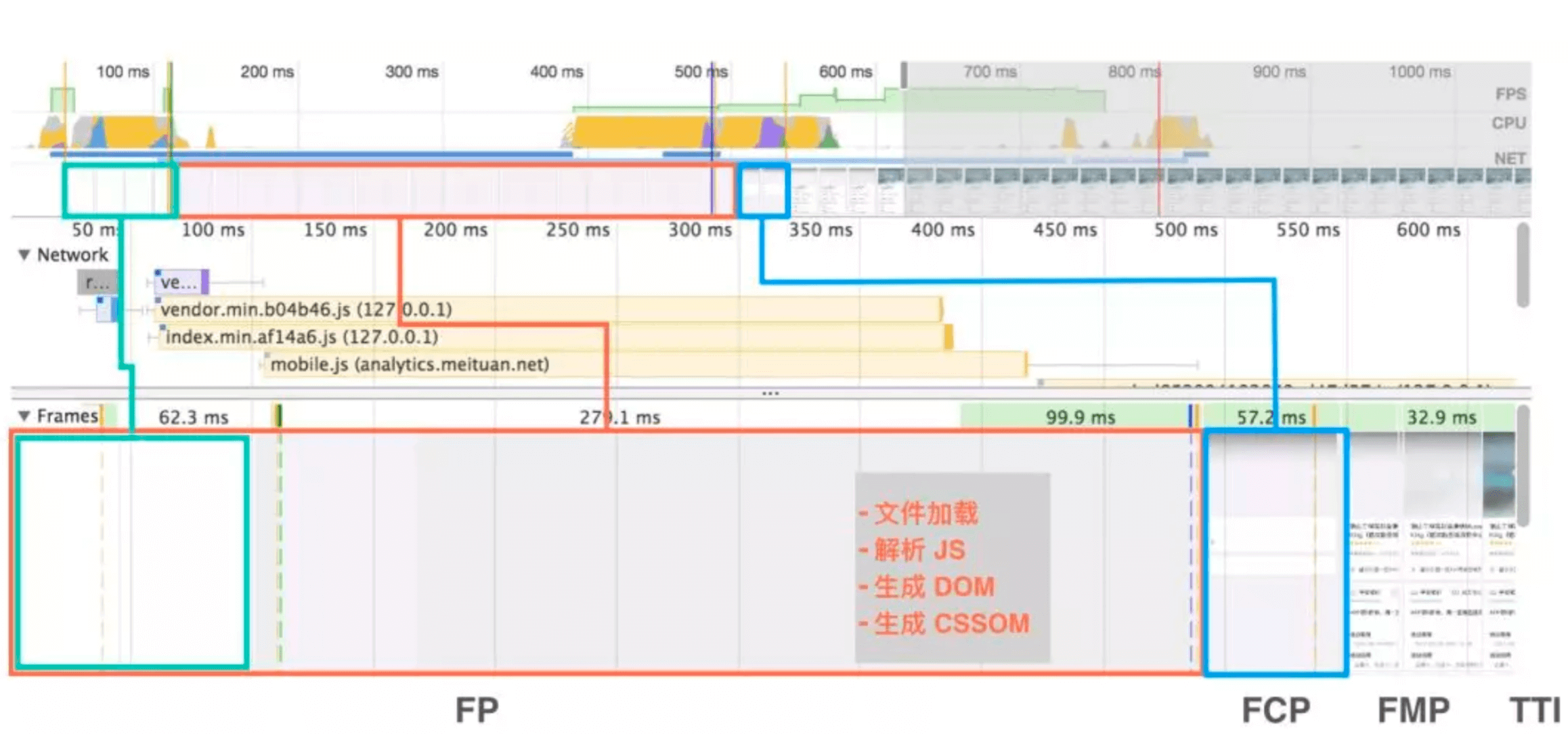
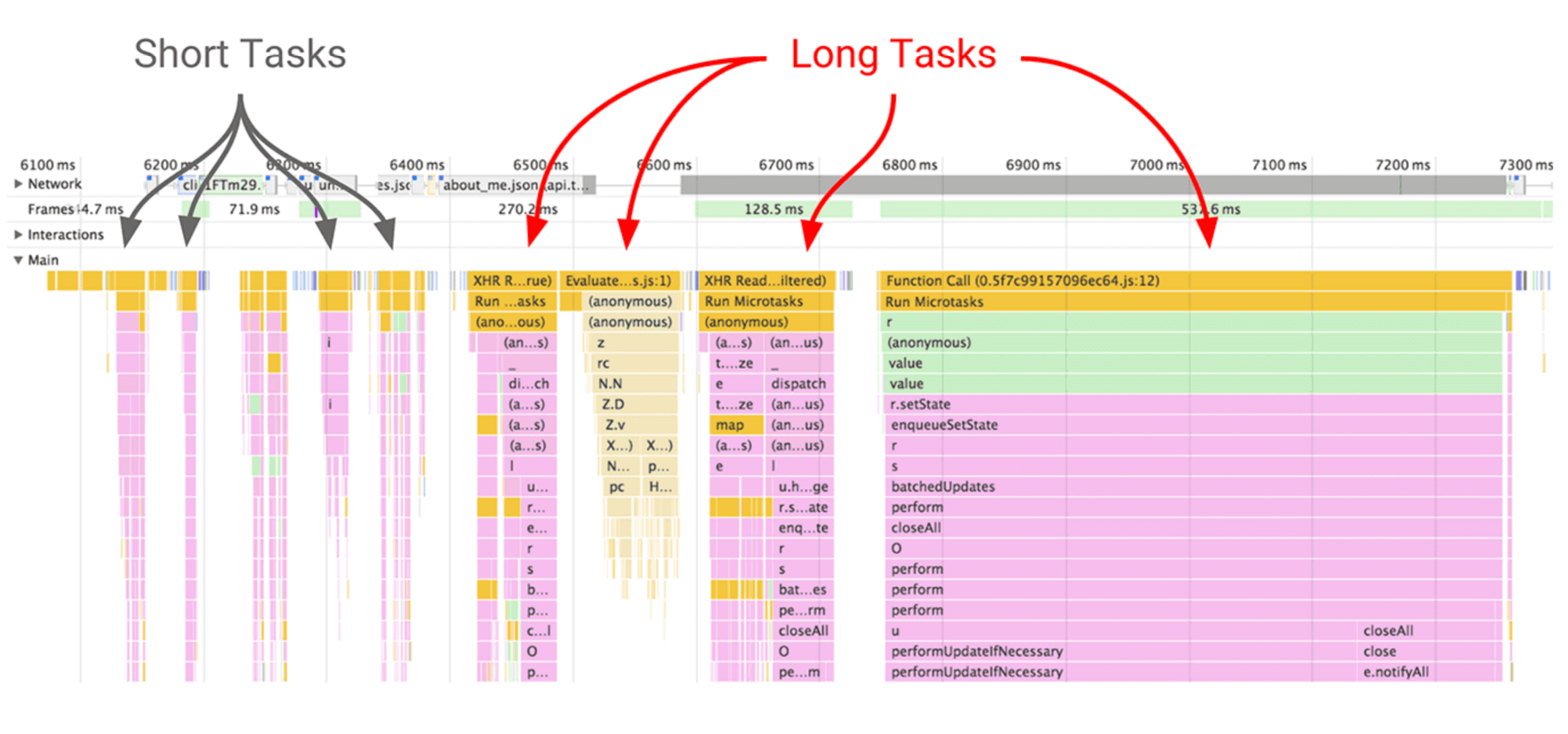
Long Task的表现
关于VUE的执行

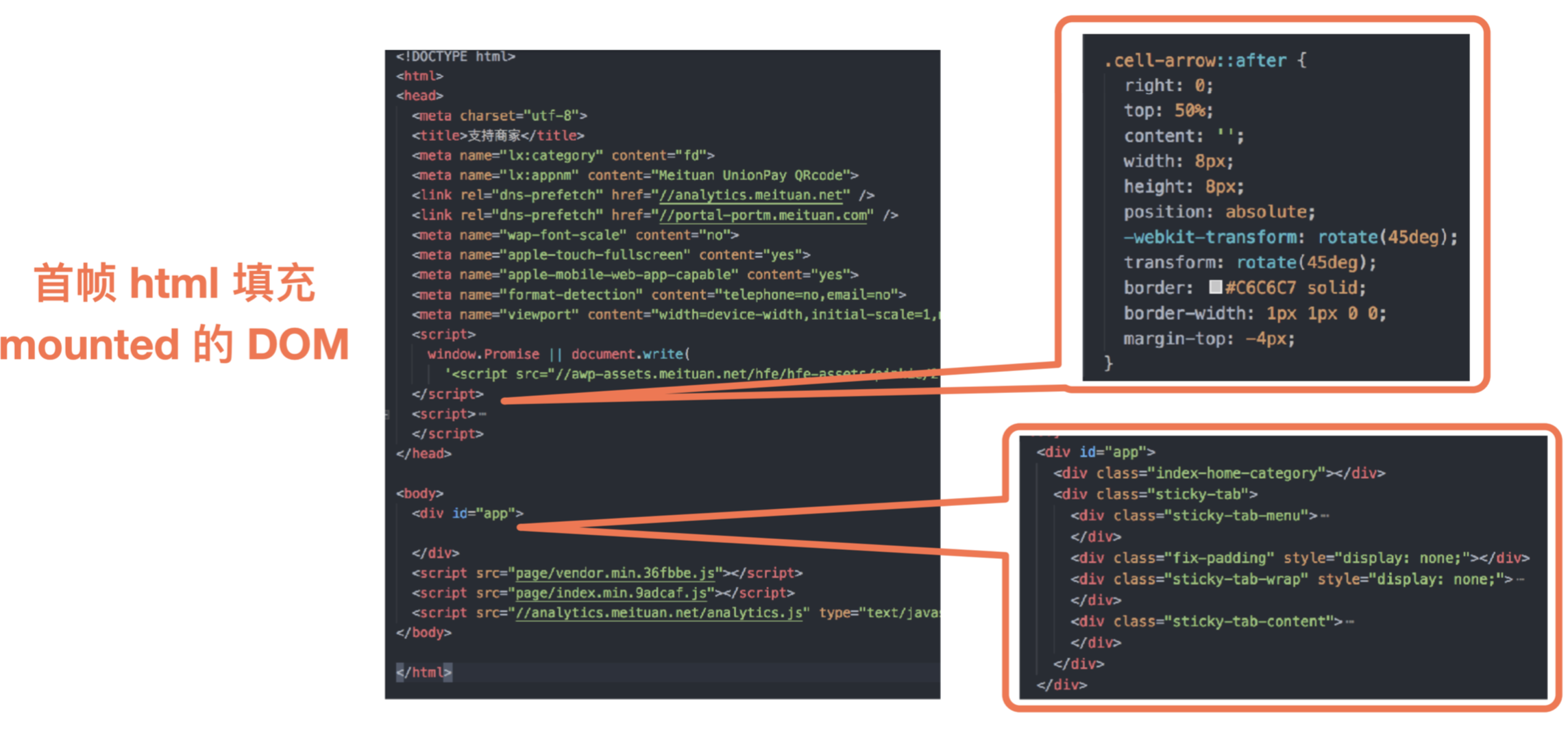
问题:为啥会出现白屏
# CSR与SSR

# NodeJS性能优化
内存回收
内存快照
压力测试
监控异常